

Update (12/3/2021): For an updated approach please visit here.
The most important thing to keep in mind while doing DDD (Domain Driven Design) is to focus on business domain problems, and model the domain so it reflect the ubiquitous language spoken by domain experts. It is true that we inherently should not worry about the persistence mechanism, because rightfully so, it is an implementation detail that the domain should not need to worry about.
Yet what is a software worth if it doesn’t … well “implement” things? I would say just as good as your white paper concept.
We basically have two options for persistence while doing DDD:
- Use domain models as persistence model.
- Use separate domain & persistence models.
Going with the 1st approach we get benefits such as:
- One set of models to maintain.
- “Usually” faster initial release of the software.
- ORM change tracking feature (A big one).
While the first two points aren’t really that big of a deal (Since it highly depends on the quality of the developers and the organizational culture). The 3rd one is definitely an important point, as it would be very counter-beneficial to do things like Updates on the database for all rows and columns regardless whether they have changed or not.
Enough of the pros, let’s look at the cons of using the 1st approach.
Although modern ORMs (EntityFramework, NHibranate etc) do give you quite a bit of control on how to map your models to the database. Unfortunately they do enforce you things like:
- Creating parameter-less private/protected constructors which you don’t need in your domain model.
- Forcing you to have setters in your properties (although private).
- Leaking persistence concepts into your domain.
- And the one I hate the most: They make your life tough to work with many-to-many relationships, while you often don’t even need those in your domain because you can denormalize a M-to-M into a O-to-M (Check out this great article from Udi Dahan on this subject). It forces you to define domain concepts like: “ProductOrders”, “StudentCourses” etc which don’t make sense in the real world. Domain experts know “Product”, “Order”, “Student”, “Course” not the above made up concepts.
- Fluent mappings/configurations of EfCore help you out with a lot of these problems (and you can defiantly make it work). But as everything that looks too good to be true, these come with caveats. It becomes increasingly problematic to manage these configurations when the domain complexity grows.
Another con of the 1st approach is the speed of releasing software versions. While it is somewhat true that v1.0 of the software is released faster (I have my doubts on this), your organization will see the impact when you come to v3.0 or v7.5 (arbitrary chosen).
But enough of sharing the domain model with persistence. Let’s look at the benefits with having separate domain & persistence models:
- You can model your domain as you like and need it, and not having second thoughts like: “Ehh … I know, I shouldn’t place this here in my domain model, but my ORM won’t be happy without it”.
- Have your domain models be aligned with Separation of Concern and adhere to the Single Responsibility Principle. At the end you want to perform business logic using these, not have them transfer your data to a persistence mechanism.
- You can go “crazy” on things like inheritance and derived classes with the DM, because that’s how you see it right. While ORMs have troubles with derived classes and such.
- ORM configurations become trivial with them having a separate PM to work with.
- Business logic is in One & only One place which is your domain workspace (be it a separate assembly or as simple as it’s own folder).
- Business logic is far more testable in DM than PM, as it has no external dependencies.
But why do so many people still go with the shared model approach?
As I have read all across the internet I found a common reason: Change Tracking.
Change tracking (CT) is the process of determining what has changed in managed entities since the last time they were synchronized with the database.
Mature ORMs like EntityFramework, NHibernate etc, come with this feature at hand and i have to say it is a wonderful feature to have (Though it adds overhead when loading entities, but more on this later). Since CT is such a highly wanted feature it is more than natural for developers to hesitate on separating DM from PM because you WILL loose this feature when you do so.
While browsing forums and sites like stack-exchange you see questions related to CT when separating DM from PM. And all the answers shift away the focus of the question.
“The persistence is a mere implementation detail” — Yes, but how to fix CT problem?
“This shows you’re looking at the problem backwards” — Yes, but how to fix CT problem?
“Use CQRS…” — Yes, but how to fix CT problem?
I especially hate the CQRS answer as it isn’t an answer at all. With CQRS you get the benefit of using ViewModels/DTOs for reading data as you can do pure SQL queries against the database, and not worry about loading the whole aggregate into memory because you aren’t going to do changes to it. But the commands in CQRS still need to worry about the DM and loading & making changes to the aggregate, so you still have your CT problem in place.
People (rightfully so) just want an example of having a separate DM & PM while preserving the CT feature. That is the exact reason for this article.
Now let’s jump into the example… Shall we?
I have made a simple .NET Core console application where the DM is separate from the PM.
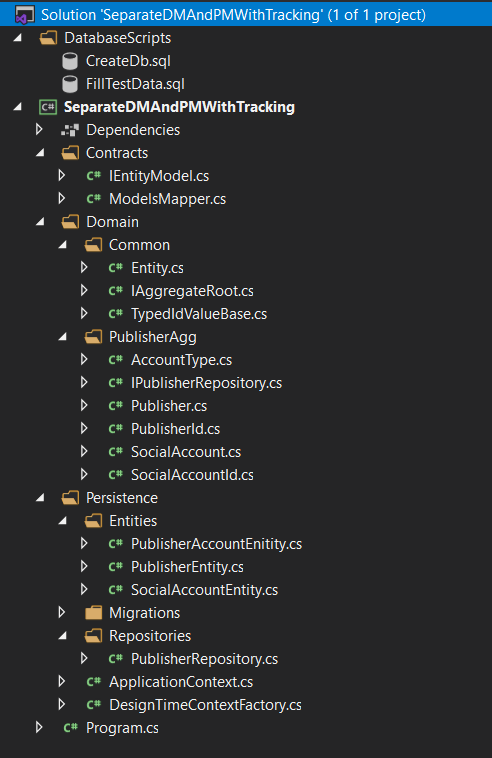
Let’s elaborate what each folder contains:
“DatabaseScripts” folder contains two SQL scripts:
- CreateDb.sql creates the database.
- FillTestData.sql populates it with some test data.
“Contracts” folder contains:
- IEntityModel interface to differentiate an entity class from a domain class.
- ModelsMapper abstract class which has two abstract methods (ToDomainModel & ToEntityModel) that the repository will implement.
“Domain” folder contains the actual domain models (where the business logic resides).
“Persistence” folder contains:
- Persistence models (Entities).
- Migrations.
- Repositories (One repository for simplicity).
- The ApplicationContext & DesignTimeContextFactory.
The domain problem revolves around the idea of Publishers and SocialAccounts and how a publisher can attach to many social accounts and one social account can contain multiple publishers (Idea came from this thread).
I found this a good example as it is a good candidate for a persistence model represented with a many-to-many relationship and a one-to-many denormalized domain model.
Publisher is chosen as the aggregate root since a SocialAccount can exist without a Publisher. Yet a publisher has only sense if it has to publish something (SocialAccount in our case). So the publisher contains a list of SocialAccounts, whereas SocialAccount doesn’t have a reference to the Publisher.
The Publisher class is the aggregate root so it handles the business invariant’s (fancy word for “rules”) for itself but the SocialAccount handles it’s invariant’s within itself.
Publisher contains it’s Id, Name and a list of SocialAccounts, and exposes method for the social account (ChangeAccountType, ChangeAccountEmail). Notice also how Publisher implements the IAggregateRoot interface (The repository can work with only objects that implement this interface).
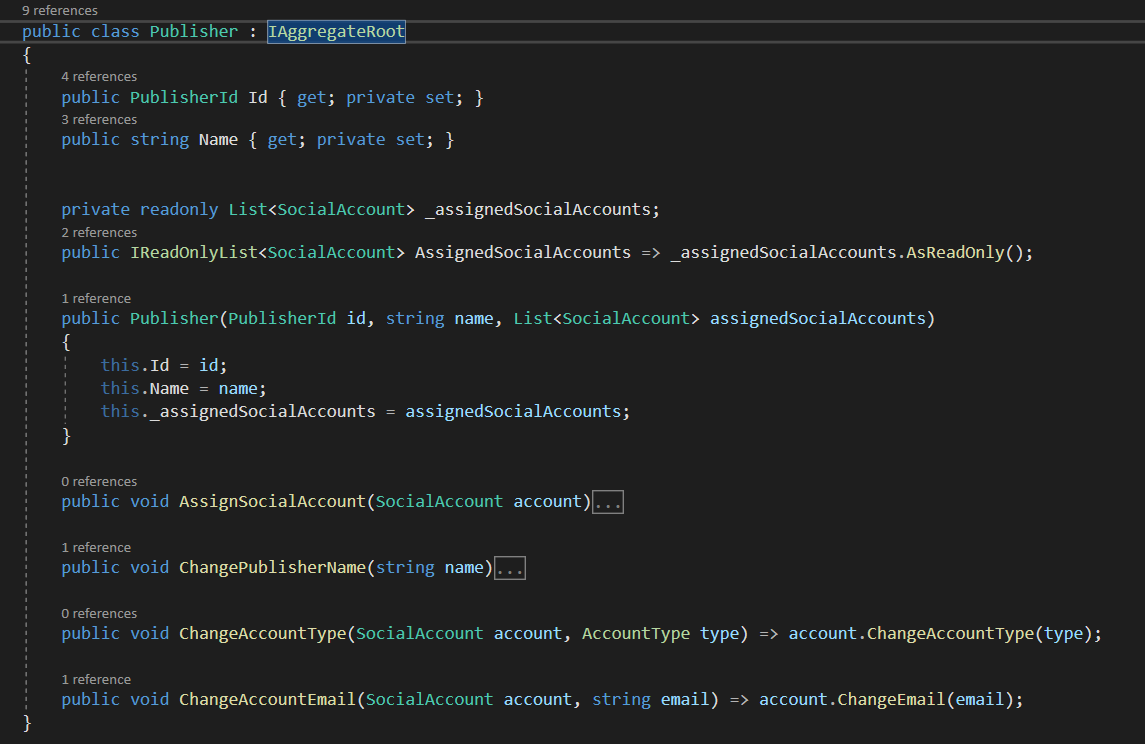
A closer look at the methods shows how the aggregate controls the business invariant’s.
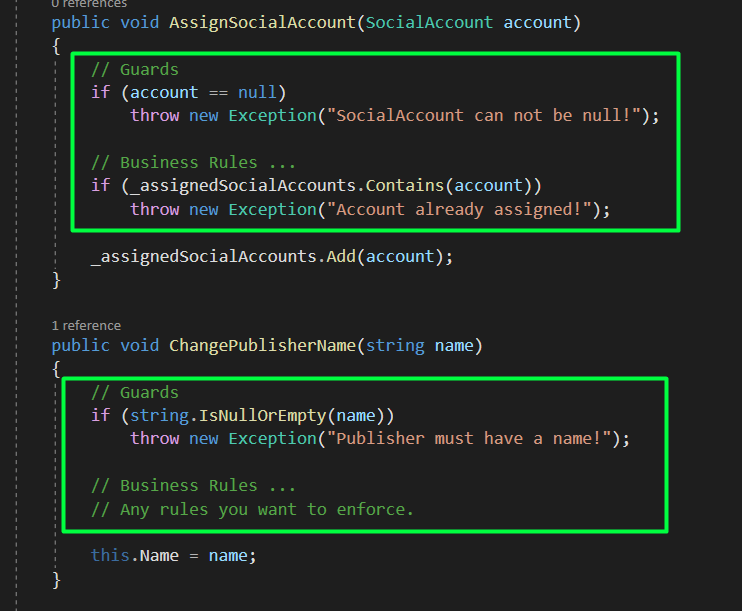
Having a look at the SocialAccount class, it contains it’s Id, Email, and AccountType (It has no reference to the Publisher). It also has methods like ChangeAccountType and ChangeEmail, which are internal and accessible only from the Publisher, yet it alone handles it’s invariant’s.
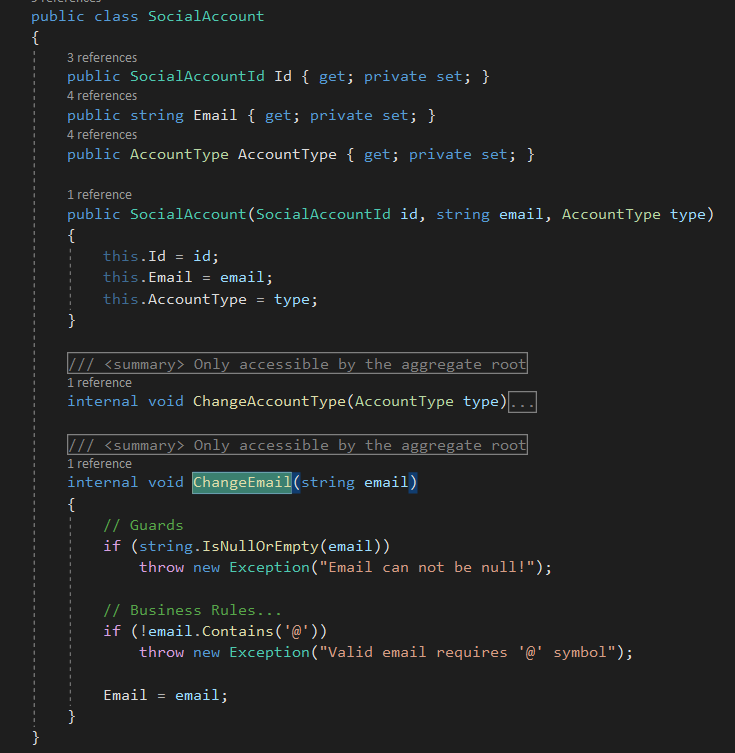
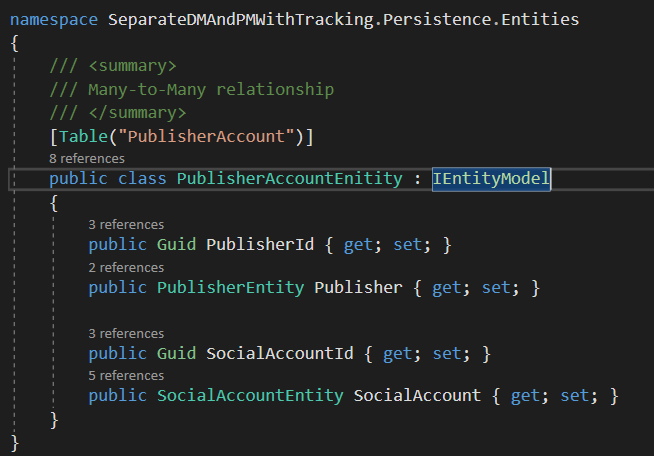
The persistence models are in the persistence folder, and here we need to introduce a new class called PublisherAccountEnitity which represents the many-to-many relationship, because the database needs it. But we are free to do that since this will not pollute our domain models anymore.
PublisherEntity contains it’s fields and a collection of PublisherAccountEnitity.
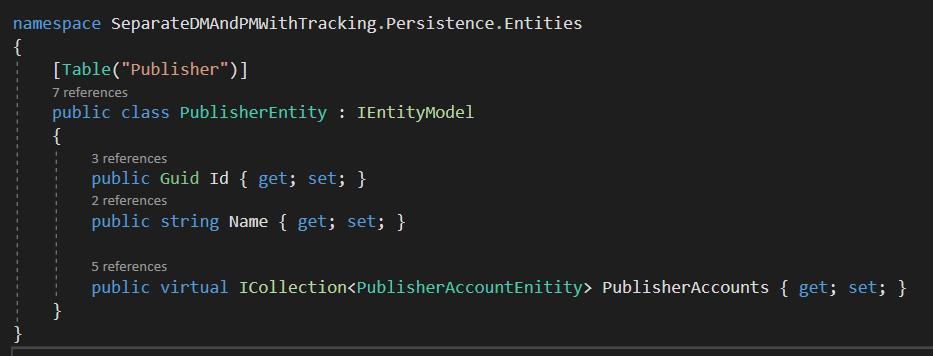
SocialAccountEntity contains it’s fields and a collection of PublisherAccountEnitity.
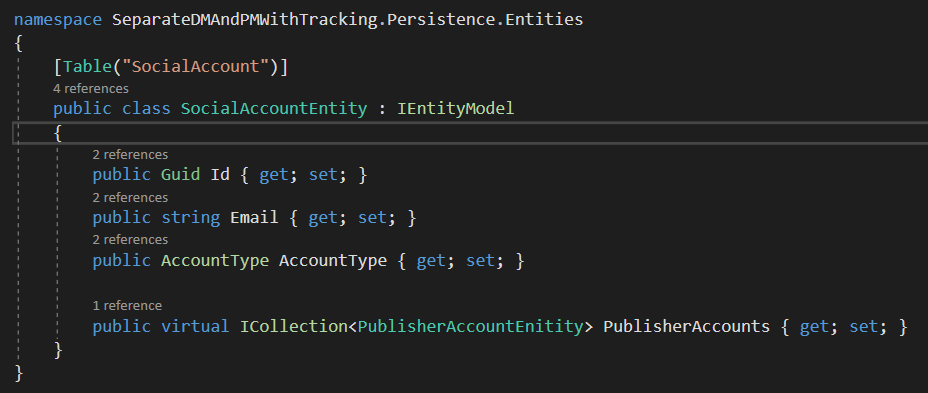
And PublisherAccountEnitity contains the PublisherEntity & SocialAccountEntity navigation properties and their respective Id’s.
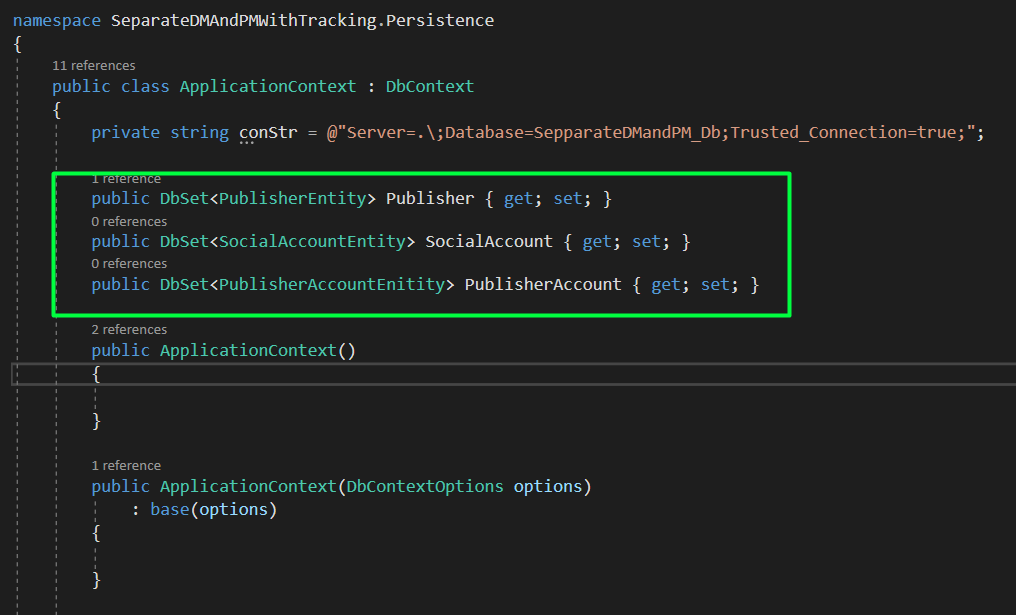
As we can see the ApplicationContext uses the persistence models rather than the domain models.
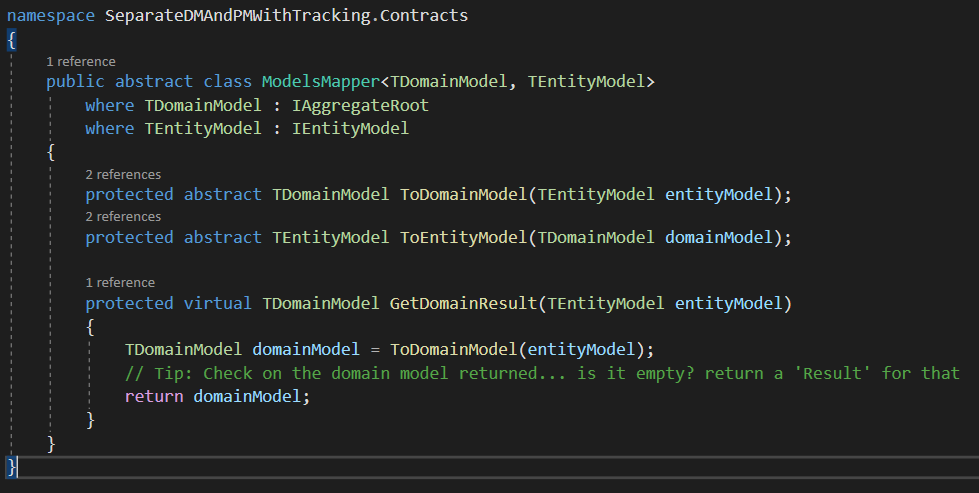
Having a look at the ModelsMapper class we see it is a generic abstract class with parameters of type TDomainModel (which needs to be an object that implements IAggregateRoot), and TEntityModel (which needs to be an object that implements IEntityModel). It contains also two abstract methods ToDomainModel & ToEntityModel and also a virtual method called GetDomainResult which internally calls the ToDomainModel method and returns a domain model. Because the repository should return domain models and not persistence models.
Idea behind the GetDomainResult is that in enterprise solutions you may not want to simply “Get” the domain model, but you might wrap it around a Result object and transfer error codes such as “not found”… You are free to override per liking as it is declared as virtual.
Let’s have a look at the PublisherRepository now. There is only one repository which is understandable since the Publisher is the aggregate root. It implements the IPublisherRepository interface defined in the domain folder, but also inherits from the ModelsMapper abstract class, and also implements it’s abstract methods.
This is where the mapping & change tracking magic will happen 😉.
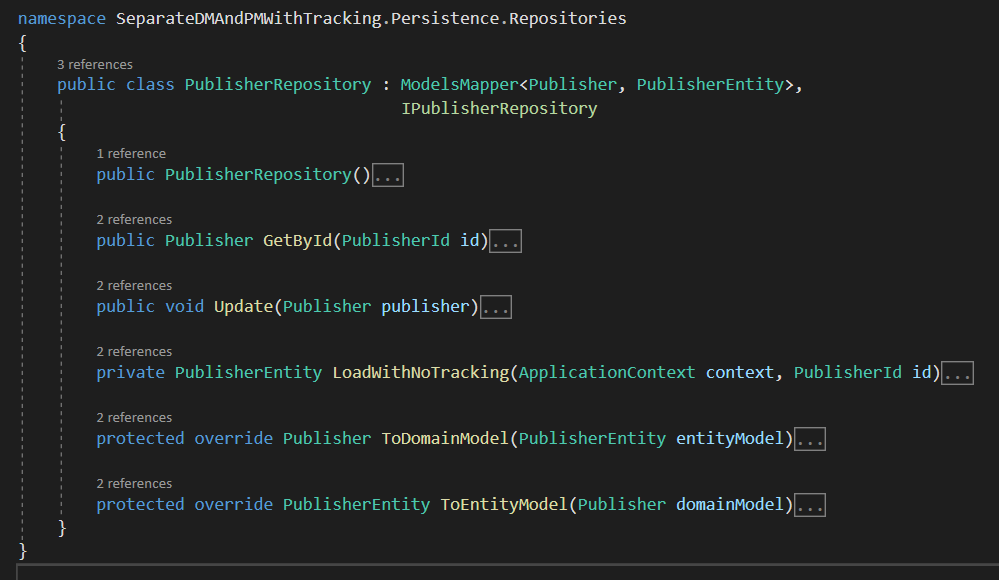
PublisherRepository implements the IPublisherRepositry ’s methods namely GetById & Update.
It also implements the ModelsMapper ’s methods namely ToDomainModel & ToEntityModel.
It also has a private method LoadWithNoTracking which is used internally to load the publisher’s data via EfCore, but with AsNoTracking used in the LINQ query expression.
The idea behind using AsNoTracking while loading the publisher’s data is that first of, it is faster, because EfCore doesn’t need to create a copy of the whole object-tree in memory. And also why would we want that? If at the end we will loose it anyway since a different instance of ApplicationContext will be used to load the publisher’s data and a different one will persist it.
The ToEntityModel method looks like below.
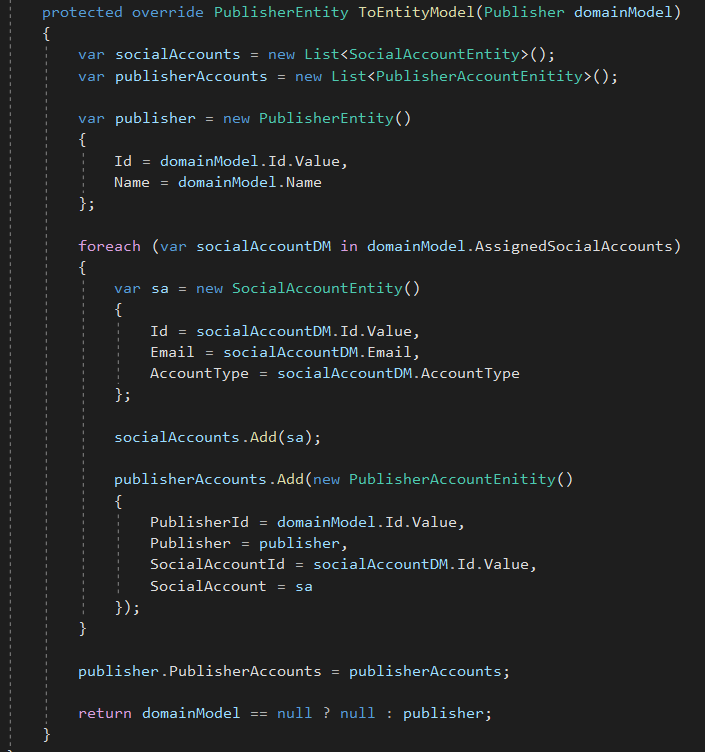
I know what you are thinking now… “Damn this is ugly!!!”. Yeah it is! Mainly because of the many-to-many relationship, but if you want to use a mapping tool like AutoMapper more power to you. I still prefer this way, because you have it in one place, you control it from here, as opposed to having mapping profiles and worrying about instantiating them at application startup. Also debugging is easier because it is coded explicitly as opposed to mapping tools which do the mapping implicitly.
A great tool I would recommend for such scenarios, where you want to have the mappings be explicit, but want to save some keystrokes is MappingGenerator by Cezary Piątek.
The ToDomainModel method looks like below.
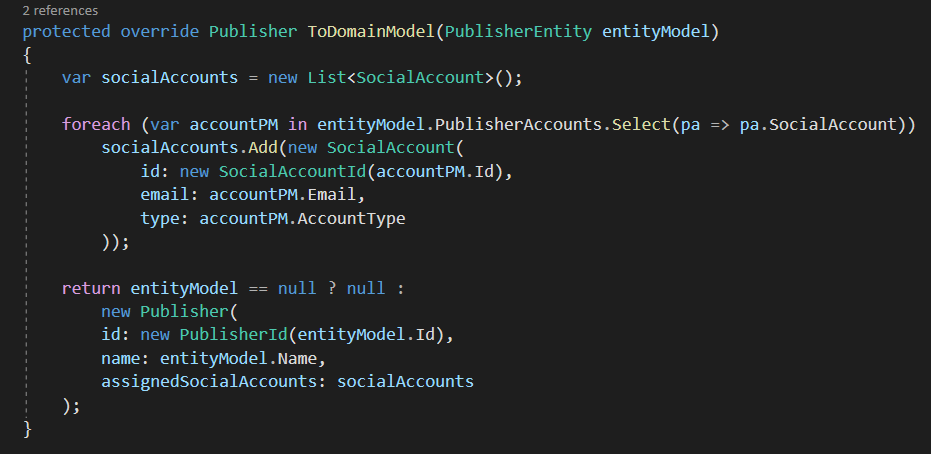
I don’t think mapping tools can help you out here, since you need to provide the necessary inputs of the aggregate root via it’s constructor to prevent an aggregate to go into an invalid state. But hey it’s again more debuggable😁.
Implementing Change Tracking
I know, I know it’s been a long read but it was necessary to understand the whole problem (and solution 😉).
Jens Theisen has written a wonderful library called Reconciler. It is available for EF6 & EfCore. It is similar to GraphDiff but it also supports EfCore.
It is a set of extension methods for Entity Framework code-first approach, that allows you to save an entire detached model/entity, with child entities to the database, WITHOUT updating all the rows & columns, if they did not change.
We can see below the code in the Update method in the PublisherRepository.
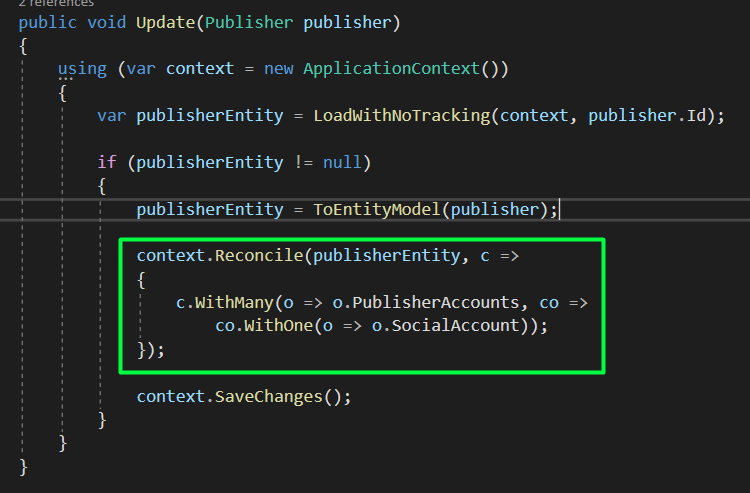
- We first load the publisher into the publisher entity object (with no tracking).
- Check whether it exists or not.
- Convert our publisher domain model to an entity model.
- Use Reconciler to identify the changes between the two entity models (if any).
- Call SaveChanges.
Let’s see it in action!
At this point we have created the database and run the script to populate it with test data.
Run the below T-SQL query in SSMS to get the result as show in the picture.
select
p.Id as [PublisherId],
p.[Name] as [PublisherName],
sa.[Email] as [SocialAccountEmail],
case
when sa.AccountType = 0 then 'FaceBook'
when sa.AccountType = 1 then 'Twitter'
end as [SocialAccountType]
from dbo.[PublisherAccount] pa
inner join dbo.Publisher p on p.Id = pa.PublisherId
inner join dbo.SocialAccount sa on sa.Id = pa.SocialAccountId
order by [PublisherName]
We can see “John” is publisher and has two assigned social accounts each with separate email’s and account type’s. And “Kelly” has one assigned social account.
In Program.cs we do the following to test our simple application:
- We load the publisher aggregate that corresponds to “John”.
- Change John’s name to “Derrick”.
- Change the email “juile@microsoft.us” to “juile@netflix.io”.
- Persist the changes.
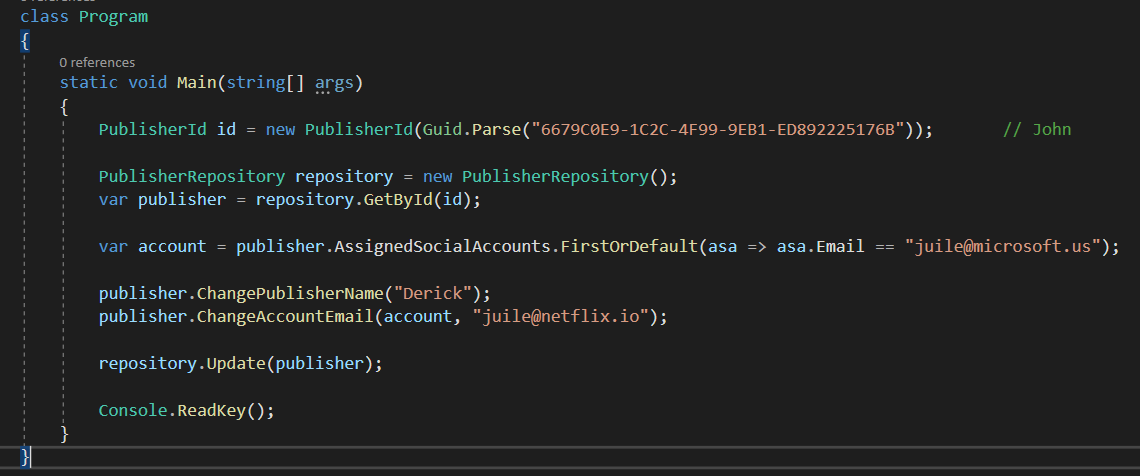
Let’s run “SQL Profiler” and see the T-SQL generated.
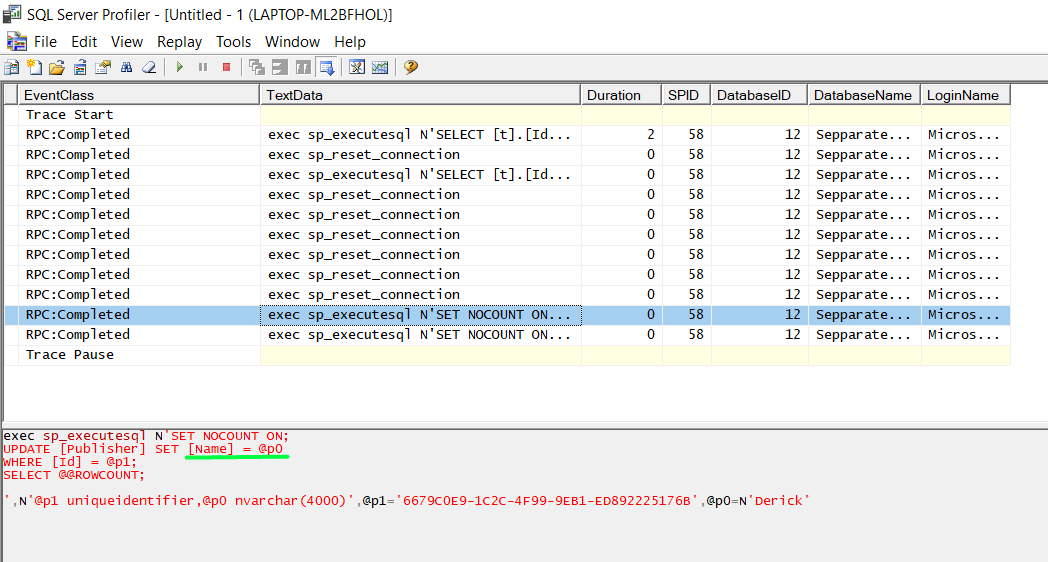
Notice how only the [Name] column is being updated since that is what has really changed from the previous state of the publisher.
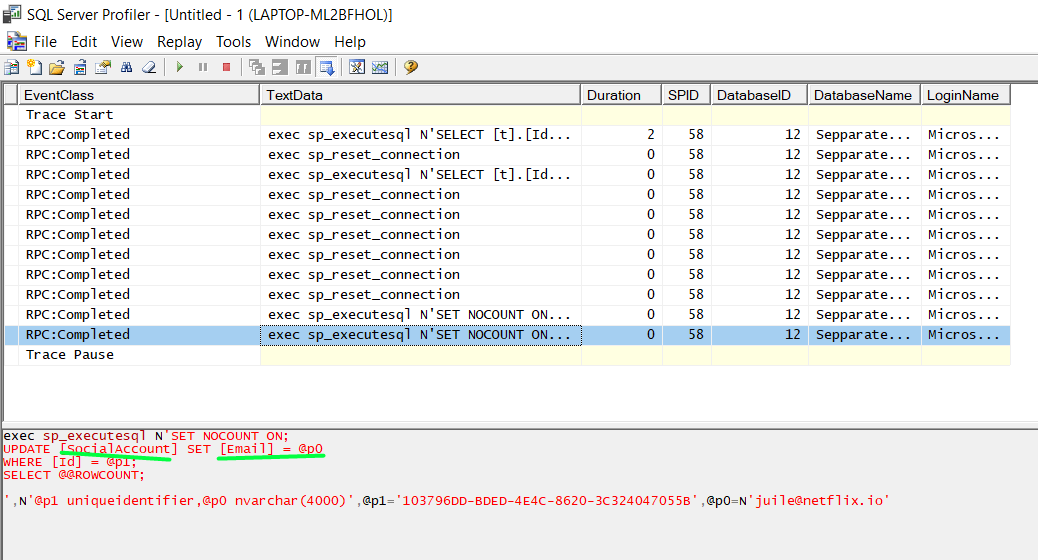
Notice how only the [Email] column is being updated since that is what has really changed from the previous state of the social account.
Notice also that the other social account with email “anthony@hotmail.com” is not part of the SQL query because we didn’t do any changes to that child entity of the publisher aggregate.
Tip: If we do update multiple child entities and want to use a “batch update” we can use EFCore.BulkExtensions to get maximum performance, while still having separate domain & persistence models🎉.
Summary
In this article I have elaborated the case of doing Updates but the same holds true for Inserts & Deletes. Simply use Reconciler’s DbContext extensions within your repositories Add, Update, Remove methods and you are good to go.
But seriously have a look at EFCore.BulkExtensions you can make your application much more performant by using Bulk methods for Inserting, Updating and Deleting multiple records as a single batch query.
I hope this article helps people which are struggling to go with the separate domain & persistence models, mainly because of implementation details like change tracking and such.
If you found this article helpful please give it a share in your favorite forums 😉.
The solution project is available on GitHub.