

Introduction
I once wrote an article that dealt with improving availability of a monolithic application, but showcased how messaging can be used to achive that. That is still the case for microservices, but this time we are going to see how fallback caching can be used to improve availability.
Availability
In a software system, availability, refers to the extent to which the system is operational and accessible to users. A system with high availability is one that is reliable and consistently able to perform its intended function, even under adverse conditions or high levels of usage.
It should not be confused with responsiveness, which refers to the ability of a system to complete assigned tasks within a given time. The reason for bringing up responsiveness in this context, is because caching is mostly used to make a system more responsive.
Ensuring high availability is important for critical systems, as it can help prevent downtime and lost productivity. To achieve high availability, software systems may employ various strategies such as redundant hardware and software components, load balancing, and failover mechanisms.
One of those failover mechanisms is fallback caching.
Fallback Caching
Fallback caching is a technique used in software systems to improve the availability of a system. It involves storing copies of data or resources in a cache so that they can be quickly retrieved when needed.
'Needed', is the keyword here! Although there is nothing inherently different to caching from an operational prespective, the intented usage is what makes it different, which we can leverage to achive higher levels of availability.
Use case (the happy path)
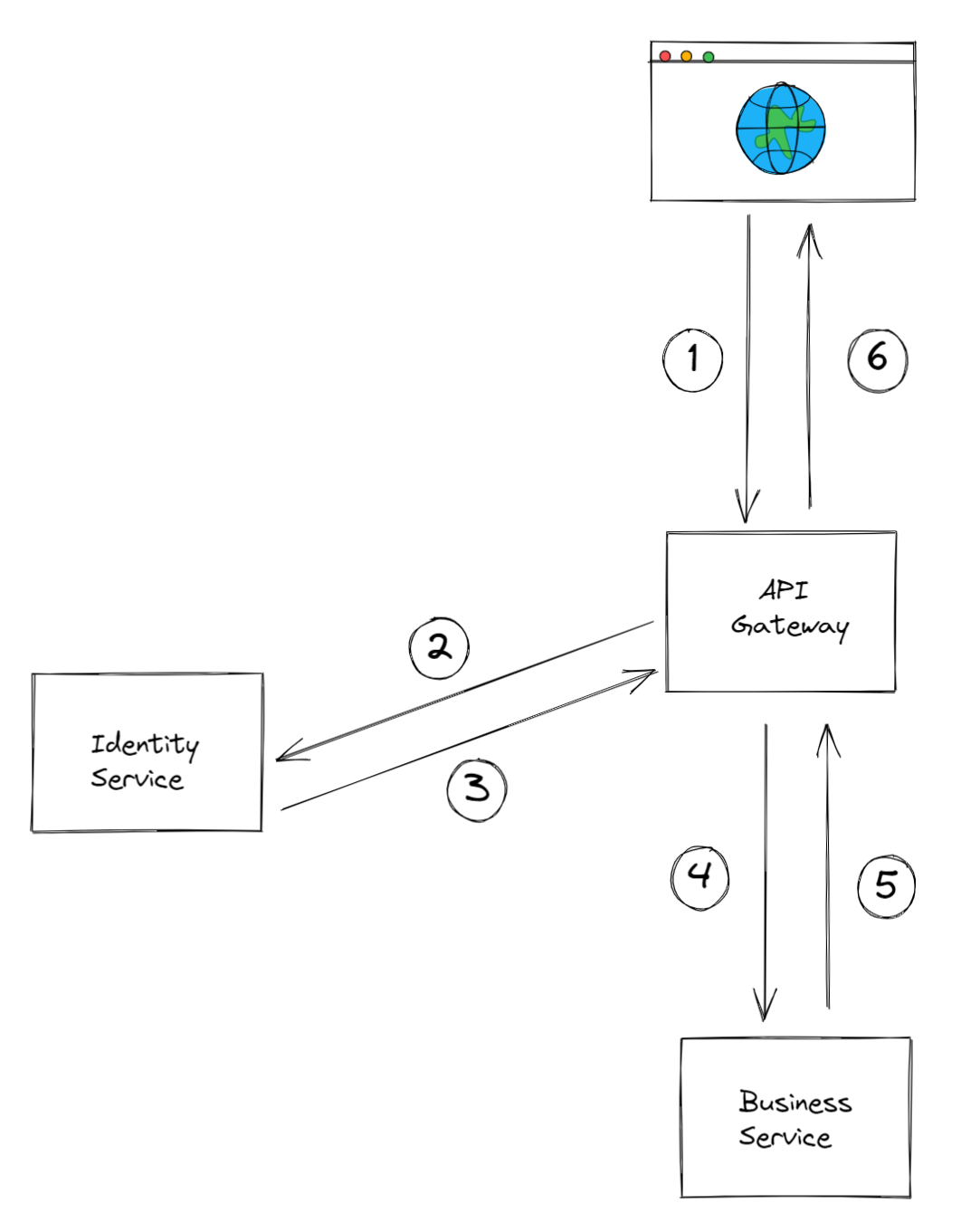
Lets take a hypothetical use case for a microservices system that contains an API gateway, an identity service, and any kind of business-aware service. A typical flow to respond to a clients request, may go as follows:
- The client makes a request to the API gateway to access a particular business capability that is offered by the business service.
- The API gateway authenticates the clients request by checking with the identity service.
- The identity service verifies clients identity, and returns back some sort of UserContext (which likley contains user claims).
- If the clients identity is verified, the API gateway routes the request to the business service.
- The business service, takes the request and starts processesing it.
- The business service, returns a response to the API gateway, which is then passed back to the client.
In this scenario, the API gateway acts as a central entry point for user requests, and manages the routing. The identity service is responsible for verifying the identity of client and granting access to the appropriate resources. The business service is the one that is aware of the specific business domain and processes requests related to that domain.
The not so happy path!
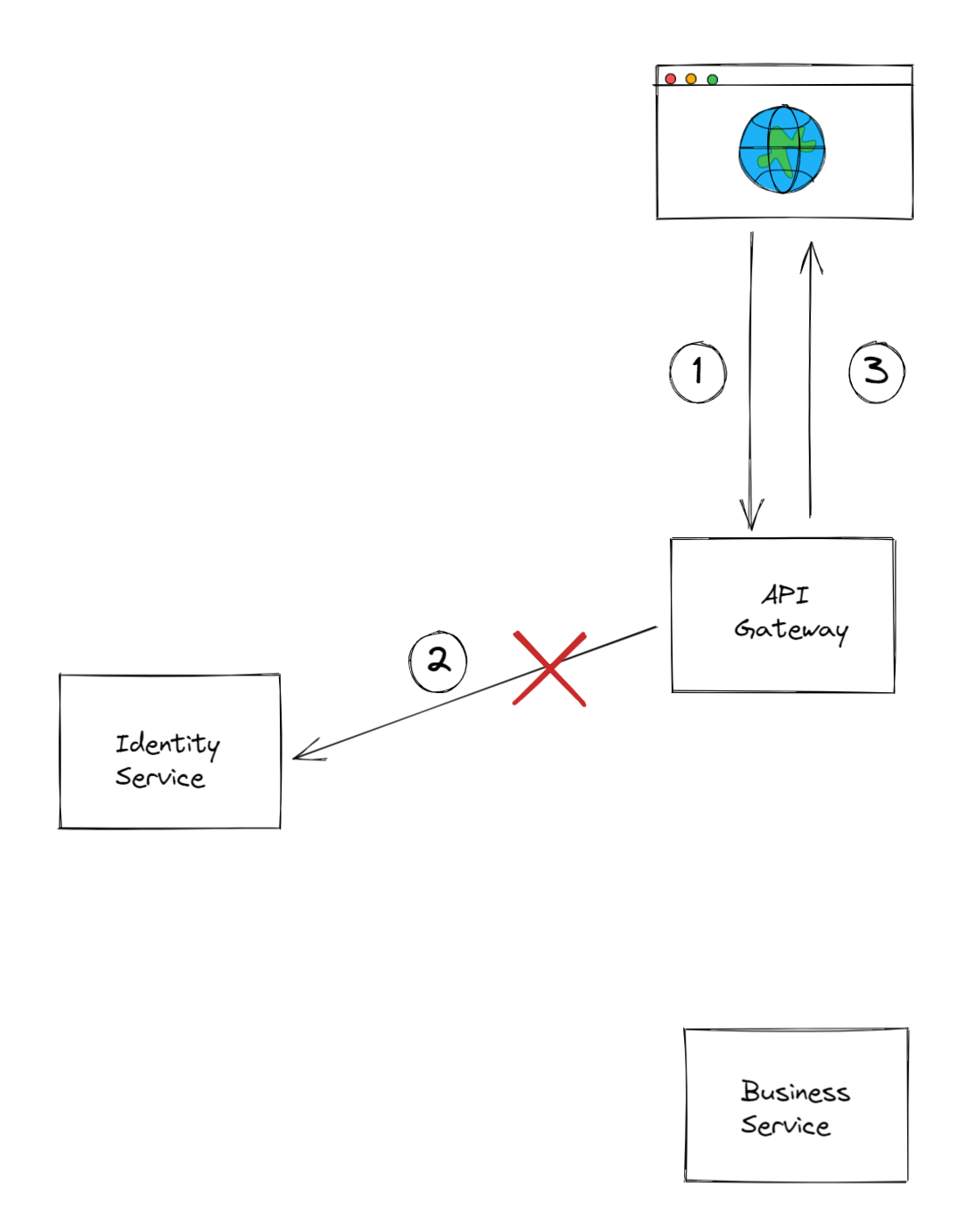
Now imagine that step number 2 fails. That is, the API gateway can't reach the identity service. This could happen for various reasons. Also, not all errors are the same, there is context behind them!
- Errors with status code 4XX, are client erros, which means that the resource server is working properly and is reachable, but the request isn't correct.
- Errors with status code 5XX, are server errors, which means that the request is probably correct, but the resource server isn't working properly and/or isn't reachable (usually due to a network failure).
At the end the client is served with an error response of some sort.
Fallback caching to the rescue
Outside your development machine, network failures are a real thing and do happen time to time. If your system is serving a lot of requests (say 1,000,000/day), and a network failure happens 0.1% of the time, that still means 1,000 requests are failing.
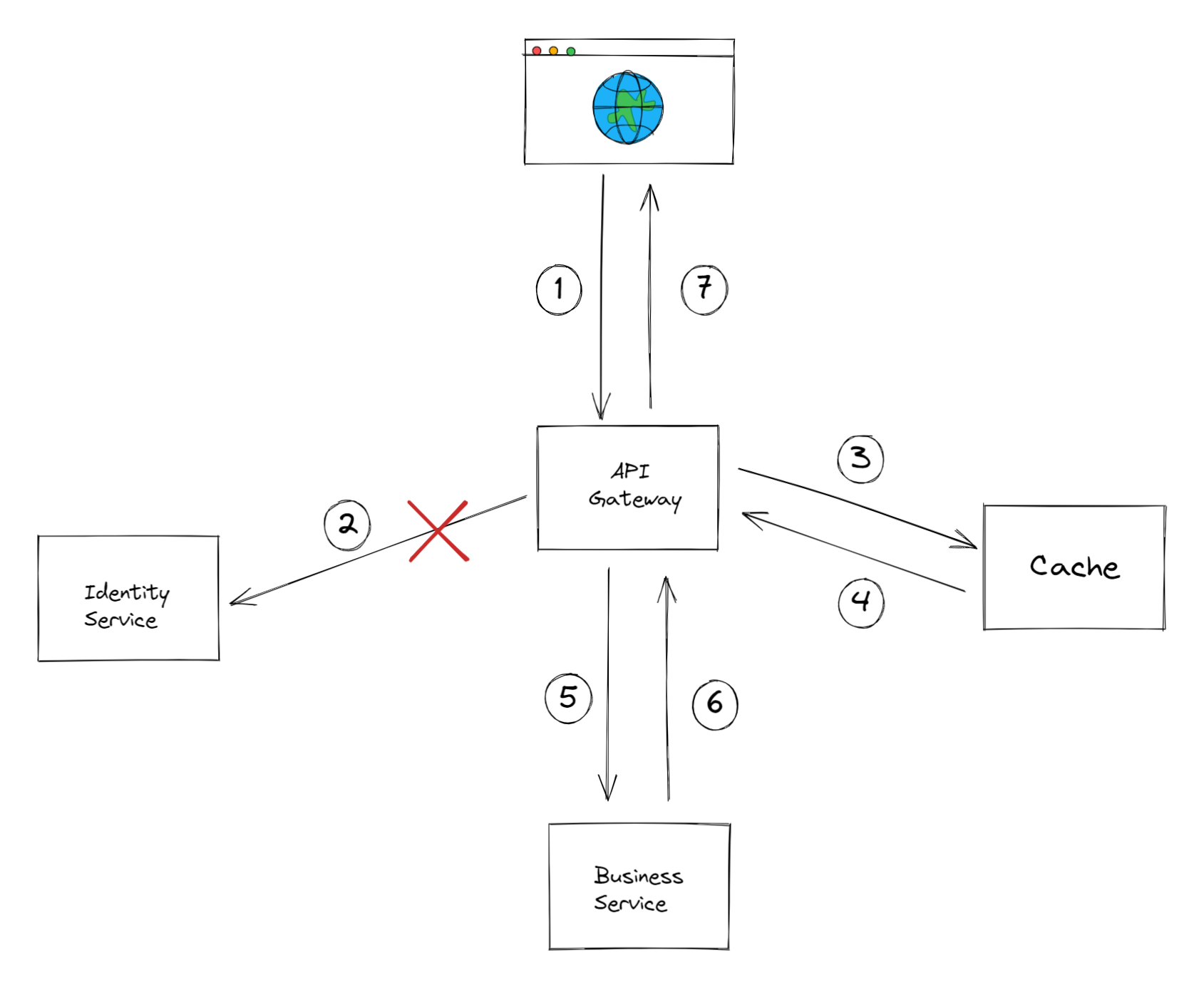
If the API gateway has access to a cache, upon a successful authentication of a user, the UserContext could be placed in the cache, but will NOT be used in subsequent requests of the same user. The only time the gateway will resort to that cached context is when there is a problem reaching the identity service (we'll elaborate on this more).
Not all errors are the same!
As mentioned in the The not so happy path section above, not all erros are the same, therefore we need to be careful when to fallback to the cached context, and when not to!
The following assumes that you are building a system which follows the standardization of HTTP response status codes.
The cached context will be used only in situations where the internal HTTP call to the identity service returns a 503 status code, indicating that the service is unavailable.
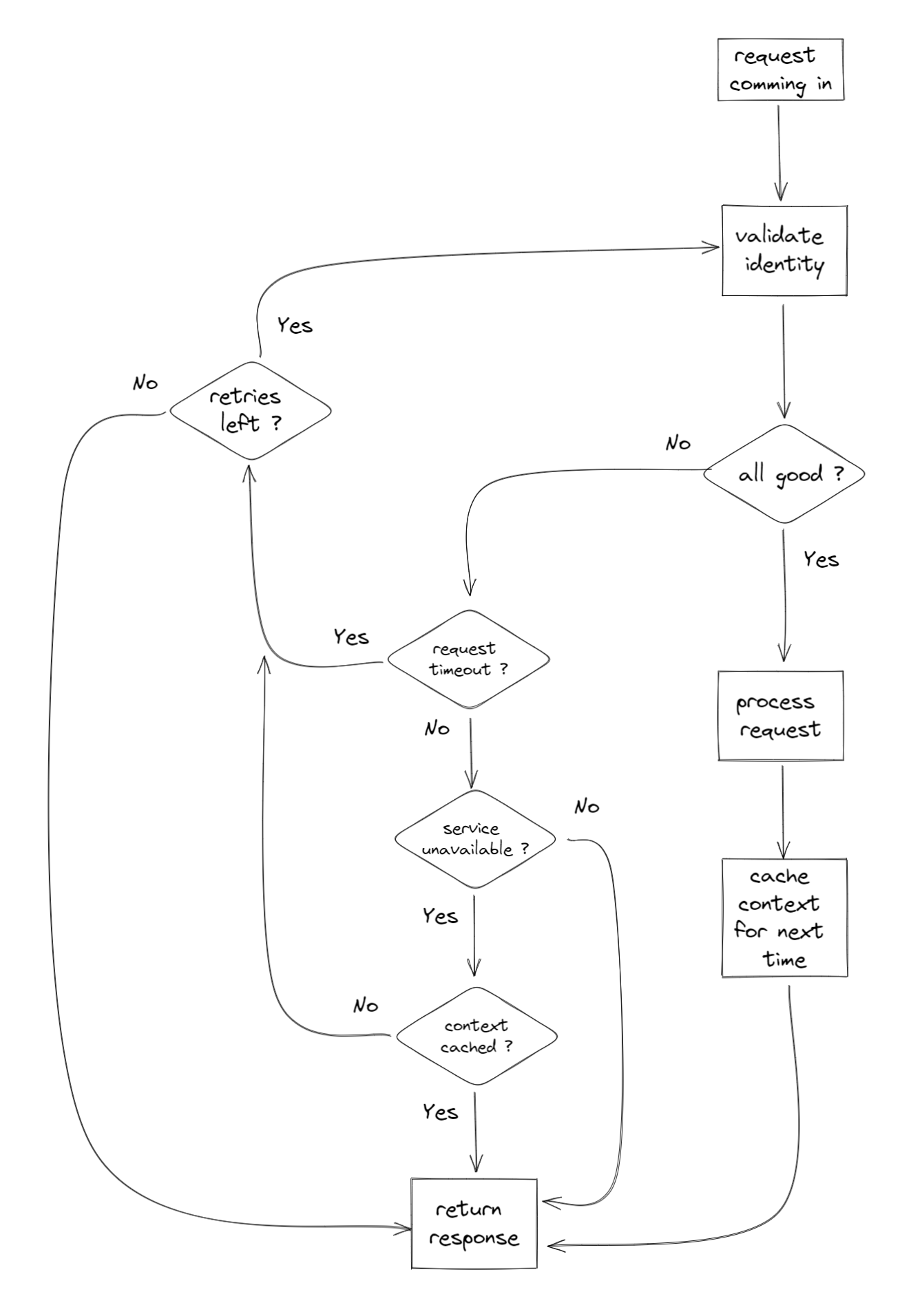
The logic goes as follows:
In case of 408 status codes (Request Timeout), it is left to the gateway to continue retrying until it gives up. Its left to retry because if this request times out, it doesn't necessarily mean the identity service is down, as other requests may reach it. This is important because these other requests might mutate the context of the user (enabling/disabling, change of permissions) which means the cached context might become an invalid representation of the real one, which makes it a security vulnerability.
In case of 503 status codes (Service Unavailable), if the UserContext does exist in the cache (which means they performed an authenticated request, prior to this one), the gateway should abort retrying, since it serves no benefit to continue, it simply impacts response time. Instead it uses that cached context to proceed and call the business service.
In case the context doesn’t exist in the cache, the gateway should continue retrying, because the alternative is returning an error code to the client, which eventually will happen if the identity service is down for a longer period of time. The cached context is OK to be used here, since 503 means that if this request can not hit the service, than others can't either, which means we are safe from a potential context mutation by a different request.
In case of all other status codes they will either "pass" in case of 2XX codes, or simply return the client error message in case of 4XX, or even 5XX (excluding 503).
Consequences
There is an overhead that must be paid with this approach, and that is the fact of adding (ever so slightly) to the response time, because of the need to update the context in the cache. We can't risk to keep an old context in the cache.
This is more apparent in case of distributed caching, where the cache is an external server. I wouldn't suggest to use such topology for this purpose! Distributed caching, is in my opinion highly valuable to ease the process of cache-invalidation of the internal services, and many other reasons, especially when dealing with multiple running instances of any given service, as that is the point of horizontal scaling.
Instead I would suggest to use local caching on the API Gateway for this purpose. You can still continue to use distributed caching for other purposes. In case where the cached context is stored in the same physical memory that is available to the process running the API gateway, the overhead of updating the cache is orders of magnitude lower (talking micro, if not nano seconds) than the process of making a network call (talking milli, if not seconds) to the identity service.
Pairing this with the fact that those, hypothetical 1000 failed requests, might have been monetary transactions, I would say its a trade-off worth taking.
Summary
In this article, we have gone through the process of increasing a microservices-based application's availability by leveraging fallback caching.
We have gone through a use case on the happy path, and a failing path. We have determined when it makes sense to use the user's cached context, and when not to use it. We have also elaborated what caching topology has the least impact on performance and responsiveness, while keeping a higher level of availability.
If you found this article helpful please give it a share in your favorite forums 😉.