

Introduction
This article is meant towards anybody who is working with Microsoft Orleans. It is an ongoing effort to collect and document any problems that I personally have had (or will in the future), and their solutions. I believe that showcasing my prespective as a consumer of this project, will help others too, as there is the factor of relatability which is absent in documentations in general.
The solutions I have presented here, may not apply in your usecase, but for the once that do ... You are welcomed!
Insufficient data present in buffer
Problem
Invoking a grain call, results in the call succeeding or failing at a random rate.
System.InvalidOperationException: Insufficient data present in buffer.Configuration
- Two silos.
- One client.
- Grain placement strategy is random placement.
- The default fallback serializer for unknown types and exceptions is
BinaryFormatter(Orleans 3.x) - Both silo hosts are ASP.NET Core applications (>=5.0).
Solution
Set EnableUnsafeBinaryFormatterSerialization=true, in each of the ASP.NET Core csproj files.
Explanation
In ASP.NET Core 5.0 and later versions, the BinaryFormatter methods are prohibited and will throw an exception, unless the developer has explicitly re-enabled those.
In this specific case the issue was that one of the silo hosts had BinaryFormatter serialization enabled, and the other did not! This explains why the grain call was sometimes succeeding and sometimes failing, at a random rate.
Because of the random grain placement strategy, the grain was sometimes being activated on the silo, which its host had BinaryFormatter serialization enabled, and was failing when the grain was activated on the silo, which its host didn't have this enabled.
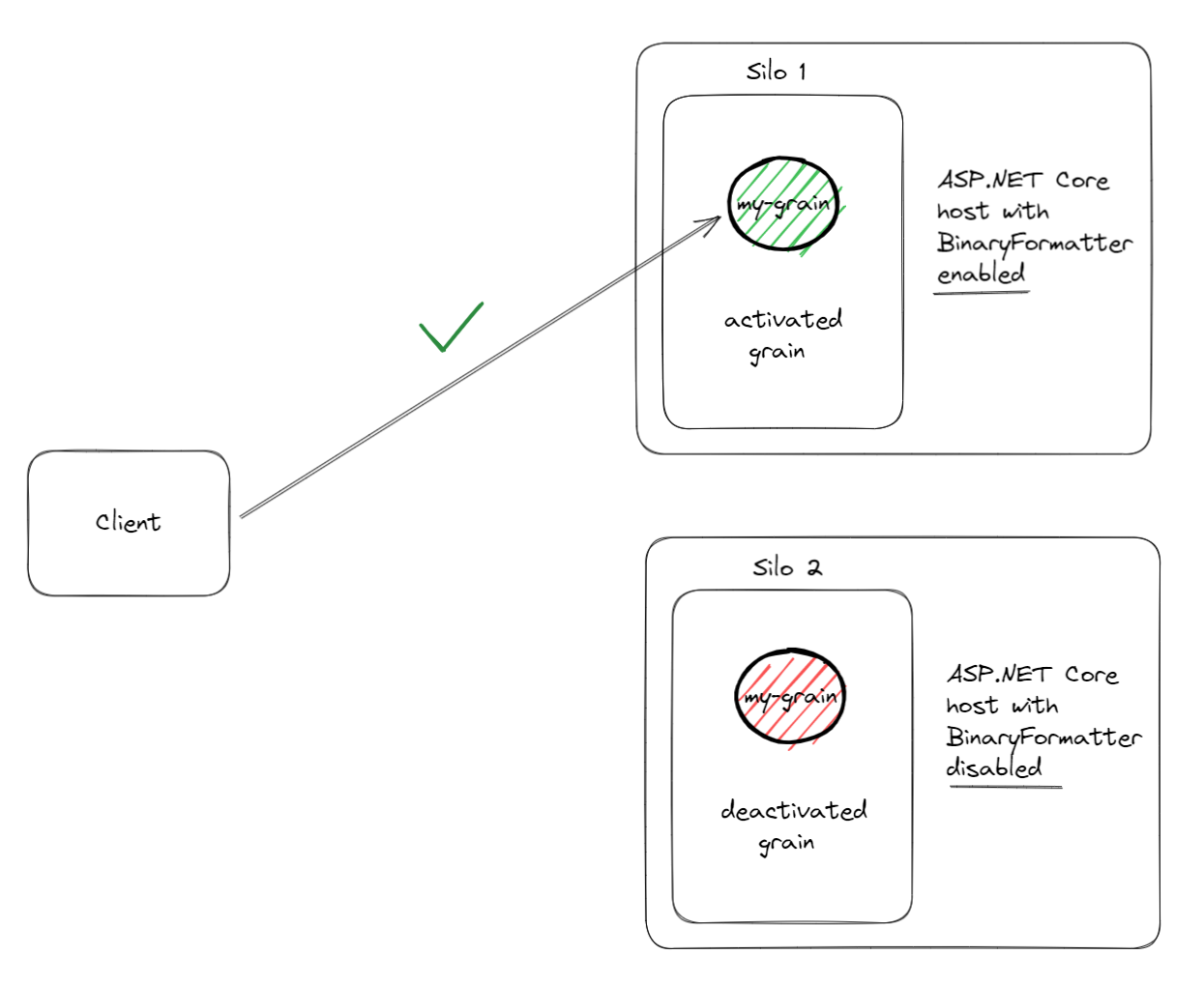
BinaryFormatter serialization enabled.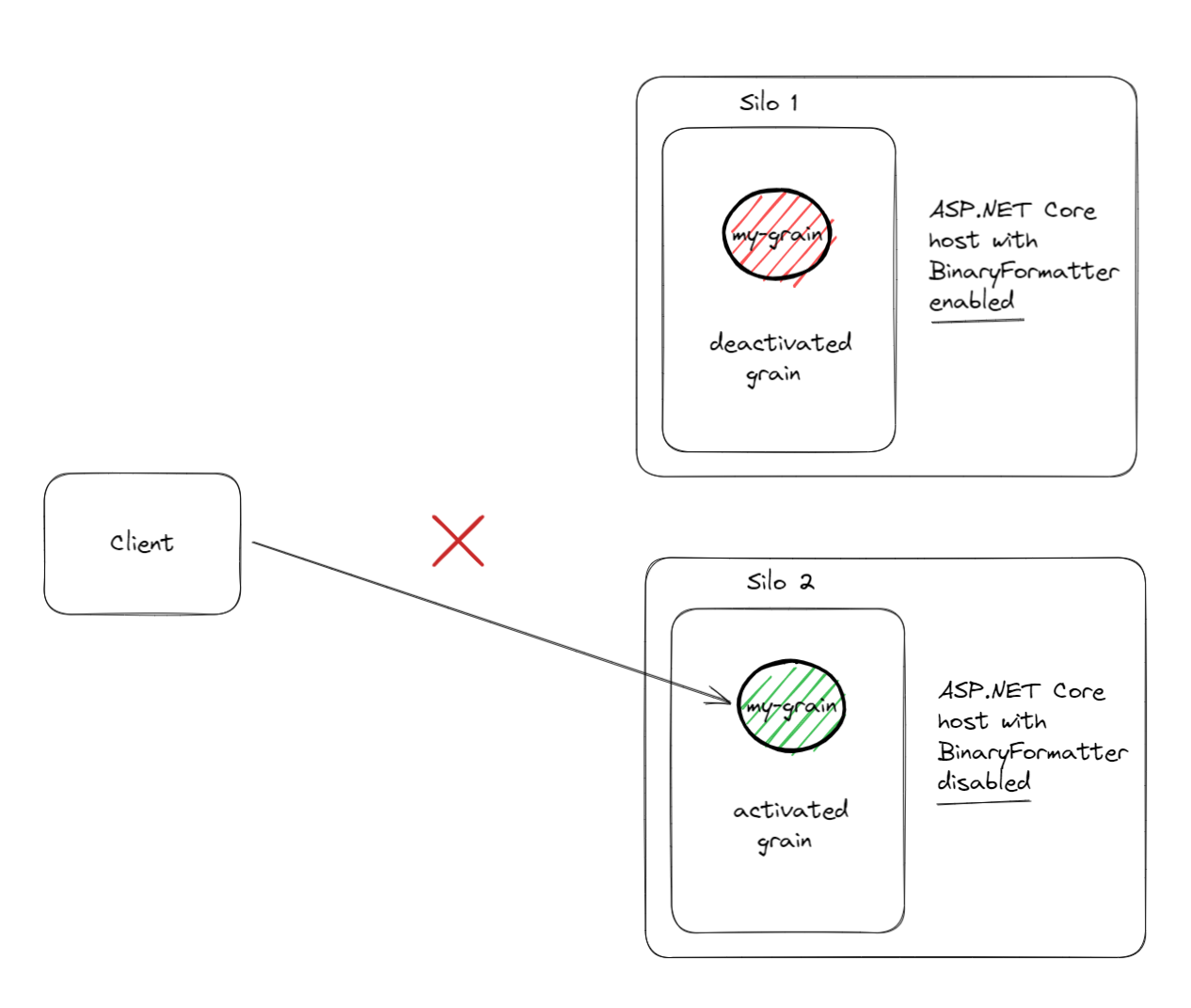
BinaryFormatter serialization disabled.I have been told I am dead
Problem
Upon startup, one of the silos would be marked as alive and the other would me marked as dead. This behavior would flip-flop, and the only consistent thing is that 1 silo was alive, and 1 was dead.
FATAL EXCEPTION from Orleans.Runtime.MembershipService.MembershipTableManager. Context: I have been told I am dead, so this silo will stop! I should be Dead according to membership table.Configuration
- Two silos hosted in kubernetes.
- No CPU limits in kubernetes deployment config file (thereby no aggressive throttling was being applied).
kind: Pod
metadata:
...
labels:
orleans/clusterId: my-cluster
orleans/serviceId: my-service-1
...
--------------------------------------
kind: Pod
metadata:
...
labels:
orleans/clusterId: my-cluster
orleans/serviceId: my-service-2
...Solution
The solution lies within the kubernetes deployment config file, specifically the serviceId must be the same value across the deployment configs.
kind: Pod
metadata:
...
labels:
app: my-app
orleans/clusterId: my-cluster
orleans/serviceId: my-service
...
--------------------------------------
kind: Pod
metadata:
...
labels:
app: my-app
orleans/clusterId: my-cluster
orleans/serviceId: my-service
...Explanation
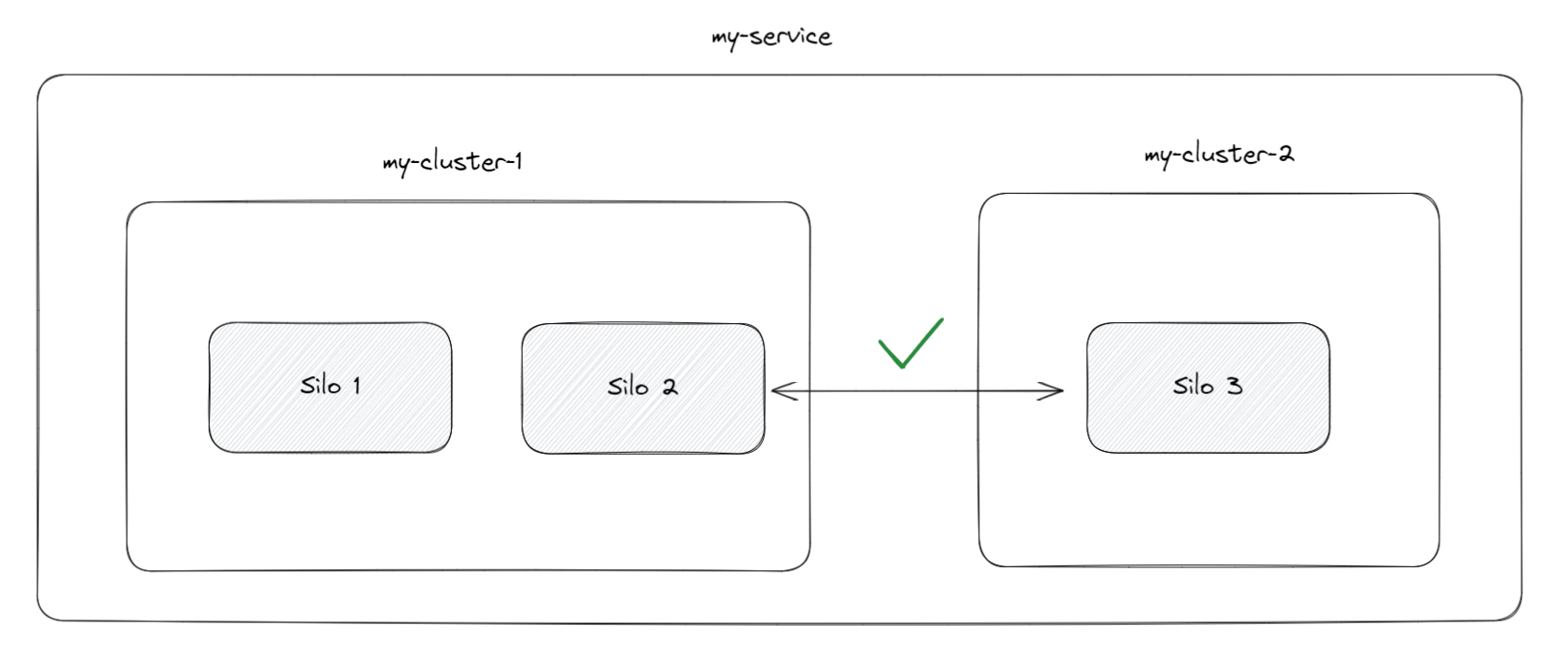
If you think from a hierarchical view, the concept of a service is a superset of a single or multiple clusters. A service is not bounded to a process, physical machine, or even data center.
In order to keep the cluster healthy, the silos ping each other to see if they are alive. Whichever was the first silo to startup, it could not reach the other silo because the config was set so that each silo lives in a different service. Due to this misconfiguration, the silos would be in different clusters also, albeit both having the same name, my-cluster.
This led to the first silo, first suspecting the second one, and than proceeding to mark it as dead.
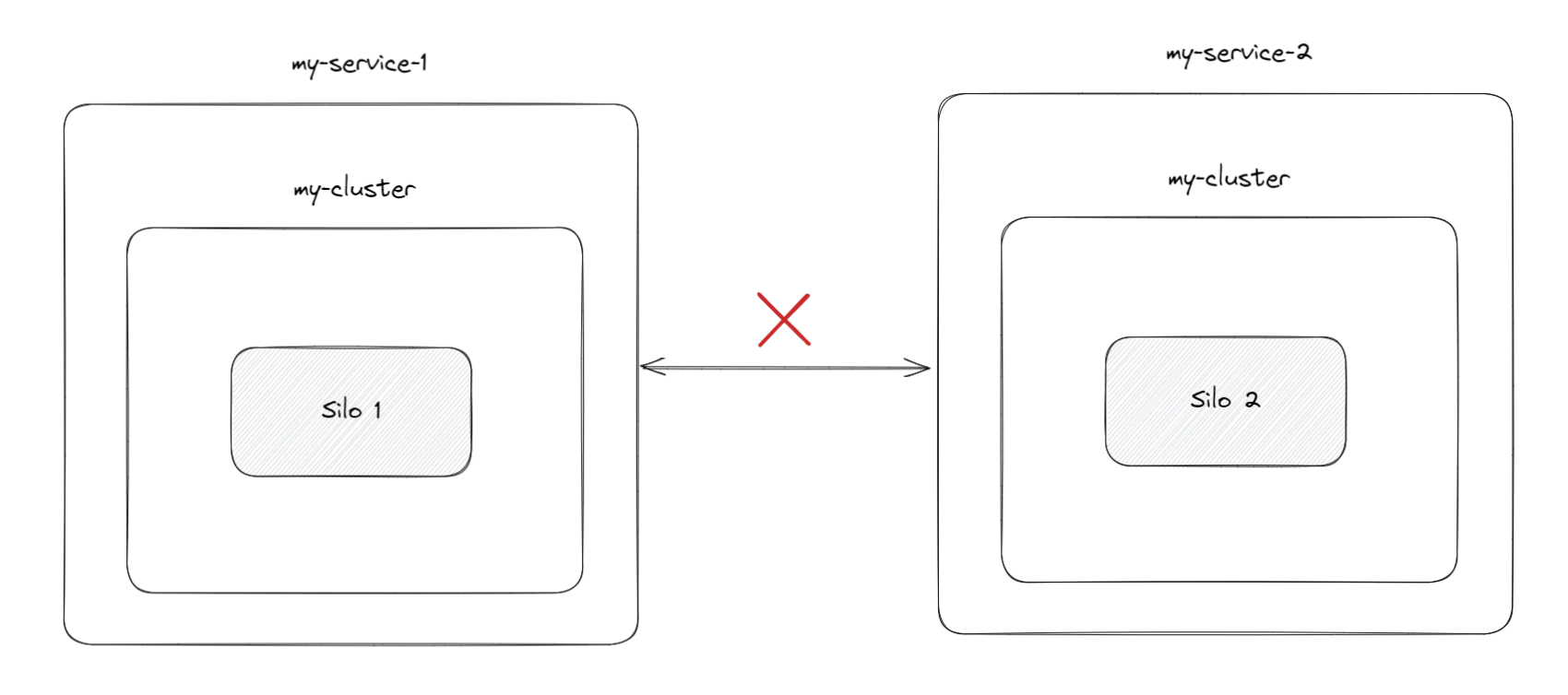
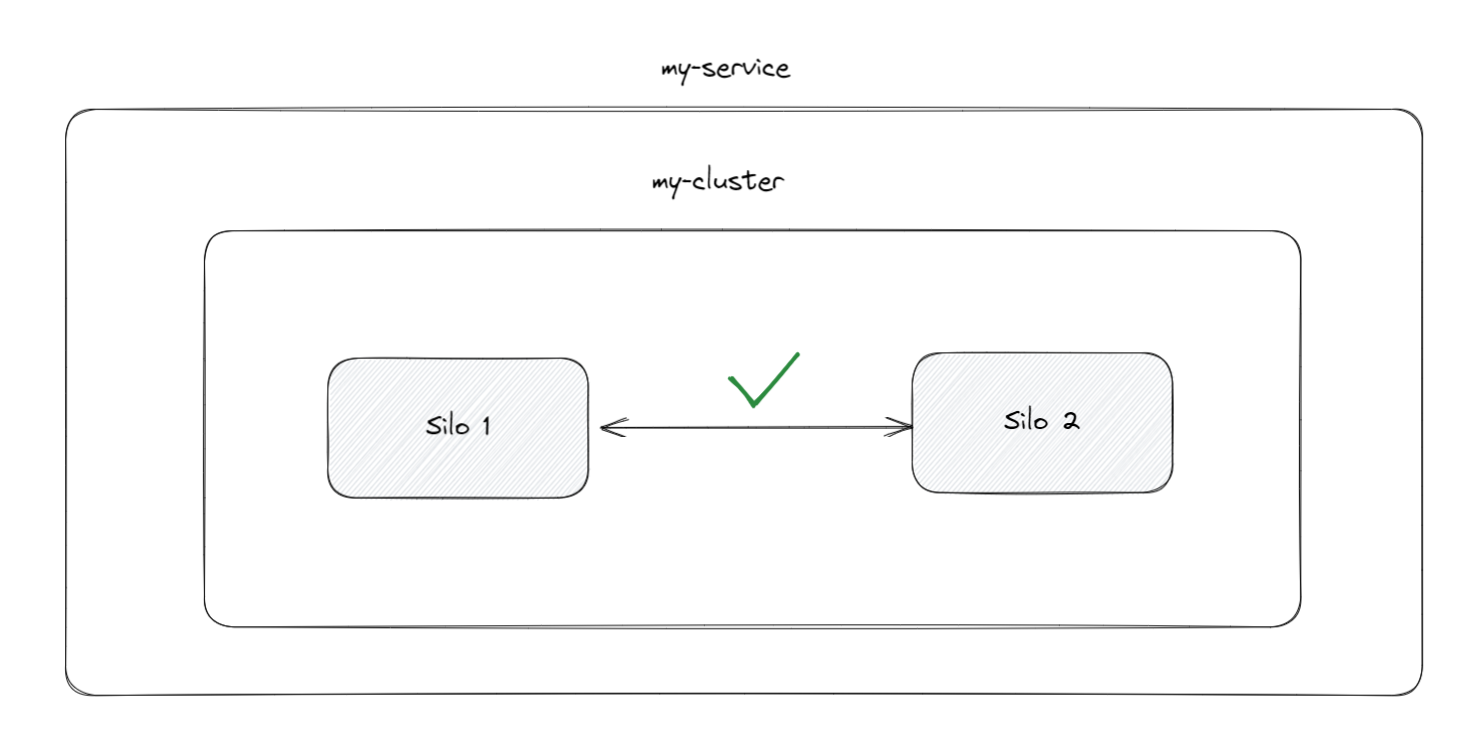
If you found this article helpful please give it a share in your favorite forums 😉.