
Tabel of Contents
- Introduction
- Relationship to SBA
- Motivation
- OrleanSpaces
- Analyzers
- Case Studies
- Summary
Introduction
"A tuple space is an implementation of the associative memory paradigm for parallel/distributed computing. It provides a repository of tuples that can be accessed concurrently."
- Wikipedia
In the ever-evolving landscape of computer science, the need for efficient and scalable solutions to tackle complex computational challenges has become paramount. As our applications and networks grow in complexity and scale, traditional programming models often fall short of meeting the demands of modern-day distributed computing.
This is where the Tuple Space model enters the stage with its unique and elegant approach to distributed coordination and communication. Developed in the 1980s and inspired by the pioneering work of David Gelernter, the Tuple Space model has been used to build resilient, adaptable, and decentralized systems that can seamlessly handle parallel tasks across distributed environments.
So, what exactly is a Tuple Space, and how does this intriguing programming model function?
At its core, the Tuple Space can be thought of as a shared repository, acting as the backbone of communication between disparate processes or agents in a distributed system. These processes interact by reading, writing, and taking tuples from the shared space, making it a powerful mechanism for synchronization and coordination.
Throughout this blog post, we'll dive into the key components of the Tuple Space model, understanding how tuples are structured and manipulated, and the fundamental operations that enable smooth interaction between distributed entities. We'll explore the benefits and challenges of this model, comparing it to other prevalent paradigms in distributed computing.
Moreover, we'll examine real-world use cases where the Tuple Space model shines, from collaborative multi-agent systems to the deployment of distributed simulations and grid computing. By the end of this exploration, you'll have a firm grasp on the potential applications of this space-age paradigm and how it can revolutionize the way we approach distributed computing challenges.
Whether you're a seasoned developer seeking to expand your knowledge of distributed systems or a curious enthusiast eager to delve into the realm of futuristic programming models, this blog post will provide you with an illuminating perspective on the Tuple Space model and its place in the vast universe of distributed computing.
Relationship to SBA
"Space-based Architecture (SBA) is an approach to distributed computing systems where the various components interact with each other by exchanging tuples or entries via one or more shared spaces."
- Wikipedia
Space-based Architecture, is a powerful distributed computing approach that emphasizes the use of shared spaces to enable seamless communication and coordination between various components in a system. The Tuple Space programming model perfectly embodies the principles of Space-based Architecture, making it a natural implementation of this design philosophy.
At the heart of Space-based Architecture lies the idea of decoupling components and promoting loose coupling among distributed entities. This decoupling is achieved by leveraging the shared Tuple Space as a global repository that fosters interaction between processes in a decentralized manner. Each process in the system can access the Tuple Space independently, eliminating the need for direct point-to-point communication and reducing dependencies between components.
One of the core features of the Tuple Space model that aligns with Space-based Architecture is its simplicity and ease of use. By abstracting away the complexity of inter-process communication and synchronization, the Tuple Space model allows developers to focus on their specific tasks without worrying about the intricacies of distributed coordination. This simplicity paves the way for more modular and maintainable code, as well as enhanced scalability and flexibility in the system.
Furthermore, the Tuple Space model promotes a data-centric approach to distributed computing. Instead of relying on complex control flow mechanisms, the model encourages processes to share data via tuples. These tuples typically consist of structured information that can be read, written, and removed from the Tuple Space. This data-centric philosophy simplifies the development of distributed systems, as it allows processes to exchange information in a straightforward manner, leading to better overall system performance.
In addition to its simplicity and data-centric nature, the Tuple Space programming model aligns perfectly with the principles of fault tolerance and resilience that are crucial in distributed systems. Since tuples are stored in the shared space, processes can recover from failures and crashes by re-reading the relevant data once they are back online. This inherent fault tolerance makes Tuple Space-based systems well suited for critical applications that require high availability and robustness.
Motivation
While the Tuple Space paradigm offers unparalled computing capabilities, it is quite the feat to get it right! A proper implementation ideally should support capabilities like:
- Scalability
- Availability
- Resiliency
- Persistence
- Transactions
- Concurrency
- Location transparancy
Hobby implementations of the tuple space fail to deliver on a lot of these, and while enterprise solutions (JavaSpaces, GigaSpaces, IBM TSpaces, etc.) do a better job at it, they usually come with a price, and put the burden of managing the spaces' state to the developer.
All of the above-mentioned capabilities come out-of-the-box with Orleans. The idea was not to reinvent the wheel, but instead leverage Orleans while providing an abstraction to the client and build features upon it.
OrleanSpaces
OrleanSpaces is a package that brings the power of the tuple space programming model into the .NET world, by using Orleans as the backbone. It is distributed as a NuGet package.
Why virtual?
Much the same way as actors in Orleans, the tuple space in OrleanSpaces can't be explicitly created or destroyed, it always exists, virtually! Its existence transcends the lifetime of any of its in-memory instantiations, and thus the lifetime of any particular server. This alleviates the developer from a lot of ceremonial/infrastructural work that would have been neccessary.
Why fully-asynchronous?
The IN and RD operations in the tuple space paradigm, are inherently blocking operations. If there is no matching tuple found in the space, then the process which has called these operations, has to wait until it gets a matching tuple. This, intrinsically has an impact on the general availability of the whole system. In OrleanSpaces these operations are done in a fully-asynchronous way, via callback channels.
When we say that IN and RD are implemented in a fully-asynchronous way, we are not referring to the non-blocking versions INP and RDP! These are sepparate concepts, which by the way are also implemented in OrleanSpaces.
Tuples
Tuples are the fundamental objects of a Tuple Space. It is a collection of ordered list of elements. There is no upper-bound limit (other than hardware restrictions) to a tuple, but there is a lower-bound limit, specifically at least a single field must be present in a tuple in order for it to be accept in the Tuple Space. The format of a Tuple is (value1type1, value2type2, value3type3, ...). NULL values are NOT allowed in a tuple.
There are two types of tuples; active and passive tuples. All the tuples stored inside the tuple space are called as passive tuples. Active tuples are those which can spawn other process or perform some function along with the calling process concurrently inside the tuple space. Once they have finished, they turn into passive tuples. Passive tuples are stored in the tuple space until they are retrieved by some process.
Examples of tuples are:
• t1 (4int, lindastring, 10.65float)
• t2 (parallelstring, cloudstring)
• t3 (25int, 100int, 99int)
In the above examples the value is given along with the type (i.e. data type of the value is given in subscript). All 3 tuples have different patterns. For instance the tuple t1 has a pattern <int, string, float> with 3 fields, t2 has a pattern <string, string> with 2 fields, t3 has a pattern <int, int, int> with 3 fields and likewise we can have many tuples with different patterns and with many number of fields.
Tuples are convertible to templates, the other way is not possible! Below we depict the same examples written using the SpaceTuple construct in OrleanSpaces.
SpaceTuple t1 = new(4, "linda", 10.65f);
SpaceTuple t1 = new("parallel", "cloud");
SpaceTuple t1 = new(25, 100, 99);Specialized Tuples
SpaceTuple keeps all the fields stored in an array of object(s), this is because it represents a generic version that can accept any (of the allowed) .NET type. While flexible, this introduces boxing when the fields are value types, which is not desired as it increase heap memory allocations, which in turn put GC pressure on the application.
Usually when multiple fields are grouped in a tuple they have some sort of correlation from a higher-level business prespective. For example, when reading a bunch of sensor data its not like these data will change the type (they are all, say: float).
For these reasons, OrleanSpaces has a lot of specialized tuples, that users can make use of. The library comes with a plethora of tuples for the most used .NET types: bool, byte, char, DateTime, DateTimeOffset, decimal, double, float, Guid, Int128, int, long, sbyte, short, TimeSpan, UInt128, uint, ulong, ushort.
Specialized tuples group all fields that belong to the same type. Below you can see instantiation of an IntTuple and a compiler error in case mixed argument types are provided.
IntTuple ints1 = new(1, 2, 3);
IntTuple ints2 = new(1, 2, "linda"); // CS1503: can not convert from "string" to "int"Equality
All tuples implement the IEquatable<T> interface where T is the tuple struct itself, therefor tuples are equatable. In the generic case when two SpaceTuples are being checked for equality, the following rules apply for them to be considered equal:
- The number of fields, must be the same.
- The types of fields on each index, must be the same.
- The values of fields on each index, must be the same.
public bool Equals(SpaceTuple other)
{
if (Length != other.Length)
{
return false;
}
for (int i = 0; i < Length; i++)
{
if (!this[i].Equals(other[i]))
{
return false;
}
}
return true;
}In the case of specialized tuples, the check for the type on the field is not neccessary as all fields are guaranteed to be of the same type. This in turn results in faster equality check. But specialized tuples employ a lot more optimizations, possible due to the strongly-typed nature of these kinds of tuples.
In the highly common case of the CPU having hardware acceleration support, OrleanSpaces leverages that to do as many parallel field checks as possible by using SIMD.
Numeric Tuples
Tuples which their underlying type are numbers, have natural support for SIMD, these include these .NET types: sbyte, byte, short, ushort, int, uint, long, ulong, float, double. Therefor the corresponding SByteTuple, ..., DoubleTuple follow this optimized path for equality checking.
public bool Equals(IntTuple other)
=> this.TryParallelEquals<int, IntTuple>(other, out bool result) ?
result : this.SequentialEquals<int, IntTuple>(other);We can see that if TryParallelEquals fails, then SequentialEquals is invoked which does the same checks as in the case of the generic SpaceTuple. Below we can see the implementation of TryParallelEquals.
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static bool TryParallelEquals<T, TTuple>(
this TTuple left, TTuple right, out bool result)
where T : unmanaged, INumber<T>
where TTuple : INumericTuple<T>
{
result = false;
if (left.Length != right.Length)
{
return true;
}
if (!Vector.IsHardwareAccelerated)
{
return false;
}
result = left.Fields.ParallelEquals(right.Fields);
return true;
}The generic parameter T has the unmanaged constraint, and the TTuple constraint which allows only tuples that implements the INumericTuple<T> interface. We perform the Length check straight-away because if the lengths are different, the tuples are not equal (in any case). This is a form of short-circuiting to avoid further computations. Note that if the hardware does not support acceleration, than the result is set to false which in-turn the calling code will fallback to sequential equality checking.
If all goes well, than ParallelEquals is invoked on the Span<T> which is a property of the INumberTuple<T> interface. This is implemented on all numeric tuples, and simply exposed the private array of the fields as a span.
internal interface INumericTuple<T> : ISpaceTuple<T>
where T : unmanaged, INumber<T>
{
Span<T> Fields { get; }
}Below we can see the ParallelEquals method which takes in two Span<T>s and performs vectorized search of the fields.
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static bool ParallelEquals<T>(
this Span<T> left, Span<T> right)
where T : unmanaged, INumber<T>
{
...
}At this point we are ensured that left and right have the same number of fields as their Length properties were the same. If the spans have a length of zero, we immediately return true as they are considered to be equal.
I have mentioned above that tuples must contain at least one field, but that is not exactly true. Upon instantiation of a tuple struct, it is possible for it to not have any fields, but it is prohibited for such a tuple to be writting in the space. It is possible for such a tuple to be returned from the agent(s) as we shall see.
int length = left.Length;
if (length == 0)
{
return true;
}If the lengths of the spans are 1, than we avoid the vectorized equality check, and do a direct index search and equality as its a single operation eitherway.
if (length == 1)
{
return left[0] == right[0];
}We represent vCount as the capacity that a vector of type T can hold (number of parallel items that can be computed at once), and vLength is the ratio between the span length and the capacity of the vector. If this ratio is equal to 0, we set the ratio to 1. We do this because it makes sense to perform a vectorized check here, since at least 2 fields are present because we excluded the cases where 0 or 1 fields are part of the spans (thereby the tuples). With at least 2 fields, we can compute the equality in parallel for those fields. Needless to say that with more fields present, the benefits of the vectorized approach increases.
int vCount = Vector<T>.Count;
int vLength = length / vCount;
if (vLength == 0)
{
vLength = 1;
}Next we loop from i = 0; to vLength (exclusive) and we cast the the spans left & right to Vector<T>(s), namely vLeft & vRight. Once they are casted to vectors, we simply proceed to doing an equality check of the vectors, which is the same as checking the actual values but in parallel. As the number of fields may very well exceed the capacity of the vector for the given type T, we loop through and cast to vectors in chunks of what a vector can hold.
For example, if the CPU supports vectors of 256 bit, and T is int, the vector can hold 8 int elements. This is because an int has a size of 4 bytes (32 bits), therefor 256 / 32 = 8.
If the following 2 tuples are being check for equality:
- <0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1>
- <1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1>
It is valid to compare them in 2 chunks of:
1) <0, 1, 1, 1, 1, 1, 1, 1> == <1, 1, 1, 1, 1, 1, 1, 1> = False
2) <1, 1, 1, 1, 1, 1, 1, 1> == <1, 1, 1, 1, 1, 1, 1, 1> = True
Therefor if any of the chunks are not equal to each other, and the rules of tuple equality require each field at the same index to be equal, it means that the overall tuples are not equal and we can bypass further checks, and return false immediately.
int i = 0;
for (; i < vLength; i++)
{
Vector<T> vLeft = CastAsVector(left, i * vCount, vCount);
Vector<T> vRight = CastAsVector(right, i * vCount, vCount);
if (vLeft != vRight)
{
return false;
}
}
i *= vCount;At the very end the variable i is multiplied by vCount and assigned to itself. This is done to take into account residual fields. For example:
platform: 256-bit SIMD
type: int
length: 30
vCount: 8
vLength: 3
1) i = 0 (handles the 1st 8 fields; 8 handled in total)
2) i++ -> i = 1 (handles the 2nd 8 fields; 16 handled in total)
3) i++ -> i = 2 (handles the 3rd 8 fields; 24 handled in total)
3) i++ -> i = 3 (skips as [3 !< vLength] = [3 !< 3]; 24 handled in total)
3) i = i * vCount = 3 * 8 = 24Next we check the difference between length and i, if this value is less than 1 it means that capacity % vCount = 0 therefor all elements have been compared, and none were different (otherwise 'false' would have been returned by now). If the difference is excatly equal to 1 we employ the same optimization technique as above by avoiding a vectorized equality check, and do a direct index search and equality as its a single operation eitherway.
If remaining > 1 then we cast the rest of the fields, starting from i (in the above example it was set to 24) till the end (6, as 30 - 24 = 6). Note that the field count by now is 6 and Vector<int>.Count = 8 so the last 2 fields are set to the default(int) which is simply 0. Think of this last operation as padding, because it allows a vectorized equality check and does not impact the end equality result. The vector of the residual fields are checked for equality at the end and if it ever came to this point, it means that all previous checks were equal, so whatever this last equality is, represents wether the tuples are equal or not as a whole.
int remaining = length - i;
if (remaining < 1)
{
return true;
}
if (remaining == 1)
{
return left[i] == right[i];
}
Vector<T> _vLeft = CastAsVector(left, i, remaining);
Vector<T> _vRight = CastAsVector(right, i, remaining);
return _vLeft == _vRight;The CastAsVector method implementation is shown below. It accepts a Span<T>, a start and a count argument. If the span length sLength is greater than the supplied count, than the span is sliced starting from start and taking as many elements as count is set. Then sLength is checked if it equals the capacity Vector<T> can hold, if its the same (this situation arises when the total number of fields is a multiplier of vCount (8, 16, 24, ...) for 256-bit SIMD, and (4, 8, 12, ...) for 128-bit SIMD) than the vector is created directly from the span by means of first reinterpreting (the readonly reference of the first element of the span) as a mutable reference, and than again reinterpreting the given mananged pointer (returned by the first reinterpretation) as a new managed pointer to a value of the Vector<T> type.
static Vector<T> CastAsVector(Span<T> span, int start, int count)
{
int sLength = span.Length;
if (sLength > count)
{
span = span.Slice(start, count);
}
int vLength = Vector<T>.Count;
if (sLength == vLength)
{
return Helpers.CastAs<T, Vector<T>>(in span[0]);
}
...
}In cases where sLength < vLength, if we try to create a vector from the span directly, it will result in a vector which has the first N items the same as the span, but the rest will not be consistent for subsequent calls, even if a second span over a memory that contains the same values of T as the first span did. That is why we need to create a temporary span with the length equal to that of the vLength for the given type T, initialize all items to T.Zero a.k.a default(T), and proceed to copy the contents of the original span into it. This is necessary because if we created the vector directly from the original span, and since sLength < vLength, the vector may contain garbage values in its remaining elements, which could cause incorrect results when compared with another vector which may contain other garbage values.
static Vector<T> CastAsVector(Span<T> span, int start, int count)
{
...
Span<T> tempSpan = stackalloc T[vLength];
tempSpan.Fill(T.Zero);
span.CopyTo(tempSpan);
return Helpers.CastAs<T, Vector<T>>(in tempSpan[0]);
}Below we can see the implementation of the Helpers.CastAs() method:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static ref TOut CastAs<TIn, TOut>(in TIn value)
where TIn : struct
=> ref Unsafe.As<TIn, TOut>(ref Unsafe.AsRef(in value));Below we show benchmarks of instantiation and equality between using a SpaceTuple with only int fields, and using the dedicated IntTuple struct for 100,000 iterations. The letters S, M, L, XL, XXL denote the size of the tuples. We see that as the number of fields increases, so does the gap of performance between the generic and specialized tuple.
| Method | Categories | Mean | Error | StdDev | Gen0 | Allocated |
|---|---|---|---|---|---|---|
| InstantiateSpaceTuple | Instantiation | 29.384 ms | 16.905 ms | 0.9266 ms | 8781.2500 | 35.1 MB |
| InstantiateIntTuple | Instantiation | 1.581 ms | 1.080 ms | 0.0592 ms | 1337.8906 | 5.34 MB |
| Method | Categories | Mean | Error | StdDev | Gen0 | Allocated |
|---|---|---|---|---|---|---|
| SpaceTupleEquality | Equality Type, SpaceTuple | 154.882 ms | 258.848 ms | 14.1883 ms | 31750.0000 | 126.65 MB |
| SequentialIntTupleEquality | Equality Type, Sequential IntTuple | 43.960 ms | 32.172 ms | 1.7635 ms | 23083.3333 | 92.32 MB |
| ParallelIntTupleEquality | Equality Type, Parallel IntTuple | 32.206 ms | 11.003 ms | 0.6031 ms | 4750.0000 | 19.07 MB |
| Method | Categories | Mean | Error | StdDev | Gen0 | Allocated |
|---|---|---|---|---|---|---|
| XS_SpaceTuple | Equality,XS | 22.177 ms | 15.596 ms | 0.8549 ms | 4968.7500 | 19.84 MB |
| XS_IntTuple | Equality,XS | 11.830 ms | 26.880 ms | 1.4734 ms | 2093.7500 | 8.39 MB |
| S_SpaceTuple | Equality,S | 42.127 ms | 14.783 ms | 0.8103 ms | 8750.0000 | 35.1 MB |
| S_IntTuple | Equality,S | 7.887 ms | 3.783 ms | 0.2073 ms | 2484.3750 | 9.92 MB |
| M_SpaceTuple | Equality,M | 80.602 ms | 18.678 ms | 1.0238 ms | 16428.5714 | 65.61 MB |
| M_IntTuple | Equality,M | 18.343 ms | 7.189 ms | 0.3941 ms | 3250.0000 | 12.97 MB |
| L_SpaceTuple | Equality,L | 152.249 ms | 79.725 ms | 4.3700 ms | 31666.6667 | 126.65 MB |
| L_IntTuple | Equality,L | 32.359 ms | 12.873 ms | 0.7056 ms | 4781.2500 | 19.07 MB |
| XL_SpaceTuple | Equality,XL | 300.282 ms | 106.343 ms | 5.8290 ms | 62000.0000 | 248.72 MB |
| XL_IntTuple | Equality,XL | 58.002 ms | 24.204 ms | 1.3267 ms | 7777.7778 | 31.28 MB |
| XXL_SpaceTuple | Equality,XXL | 591.980 ms | 477.756 ms | 26.1874 ms | 123000.0000 | 492.86 MB |
| XXL_IntTuple | Equality,XXL | 112.018 ms | 29.265 ms | 1.6041 ms | 13800.0000 | 55.69 MB |
Non-numeric Tuples
In the previous section we explored the optimized path for tuples that implement the INumericTuple<T> interfaces where T is constraint to unmanaged and INumber<T> which include these .NET types: sbyte, byte, short, ushort, int, uint, long, ulong, float, double. OrleanSpaces goes beyond these types! In addition to the previously mentioned types, the library supports also: bool, char, DateTime, DateTimeOffset, TimeSpan, decimal, Int128, UInt128, and Guid in the form of specialized tuples. Let's see one of the optimized pathways for equality checking for one of these tuples.
Looking at the implementation of the Equals method for DateTimeTuple, we see that we create an instance of the NumericMarshaller which is a ref struct, and we call an extension method on the marshaller called TryParallelEquals (same as with our numeric tuples). If it fails to perform the equality check, we fallback to sequential checking.
public bool Equals(DateTimeTuple other)
{
NumericMarshaller<DateTime, long> marshaller =
new(fields.AsSpan(), other.fields.AsSpan());
return marshaller.TryParallelEquals(out bool result) ?
result : this.SequentialEquals<DateTime, DateTimeTuple>(other);
}What the NumericMarshaller does is simply takes 2 Span<TIn>(s) and expose 2 Span<TOut>(s) which are casted from the original primitive type DateTime, to another primitive type long, in the form of properties Left & Right. Note that the TOut generic parameter is constrained to also System.Numerics.INumber<T> as the casted primitive needs to be an INumber<T> in order to leverage the vectorized equality checking. In the case of DateTime, this conversion is valid as the underlying type of DateTime is expressed in terms of ticks represented via a long property. The other non-numeric tuples follow a similar casting to a type that is an INumber<T>, always taking into account a casting that does not result in data loss, as there are more than one type to cast down to.
internal readonly ref struct NumericMarshaller<TIn, TOut>
where TIn : unmanaged
where TOut : unmanaged, INumber<TOut>
{
public readonly Span<TOut> Left;
public readonly Span<TOut> Right;
public NumericMarshaller(Span<TIn> left, Span<TIn> right)
{
Left = MemoryMarshal.Cast<TIn, TOut>(left);
Right = MemoryMarshal.Cast<TIn, TOut>(right);
}
}The extension method on the NumericMarshaller is given below. As the marshaller guarantees that the cast has been down to a type that implements INumber<T>, we can proceed to call ParallelEquals on the 2 spans exposed via the marshallers' properties. The rest is the same as in the numeric tuple example above.
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static bool TryParallelEquals<TIn, TOut>(
this NumericMarshaller<TIn, TOut> marshaller, out bool result)
where TIn : unmanaged
where TOut : unmanaged, INumber<TOut>
{
result = false;
if (marshaller.Left.Length != marshaller.Right.Length)
{
return true;
}
if (!Vector.IsHardwareAccelerated)
{
return false;
}
result = marshaller.Left.ParallelEquals(marshaller.Right);
return true;
}Below we show benchmarks of instantiation and equality between using a SpaceTuple with only DateTime fields, and using the dedicated DateTimeTuple struct for 100,000 iterations. The letters S, M, L, XL, XXL denote the size of the tuples. We see that as the number of fields increases, so does the gap of performance between the generic and specialized tuple.
Note that there is a slight penalty in speed for DateTimeTuple over a sequential version of DateTimeTuple in equality checking for very small number of fields, but this goes away with an increased number of fields, and the memory allocation is far lower with any number of fields.
| Method | Categories | Mean | Error | StdDev | Gen0 | Allocated |
|---|---|---|---|---|---|---|
| InstantiateSpaceTuple | Instantiation | 439.82 ms | 472.94 ms | 25.923 ms | 16000.0000 | 65.61 MB |
| InstantiateDateTimeTuple | Instantiation | 340.59 ms | 127.67 ms | 6.998 ms | 3000.0000 | 14.5 MB |
| Method | Categories | Mean | Error | StdDev | Gen0 | Allocated |
|---|---|---|---|---|---|---|
| SpaceTupleEquality | Equality Type, SpaceTuple | 1,317.59 ms | 1,871.96 ms | 102.609 ms | 31000.0000 | 126.65 MB |
| SequentialDateTimeTupleEquality | Equality Type, Sequential DateTimeTuple | 903.86 ms | 1,042.71 ms | 57.155 ms | 26000.0000 | 104.52 MB |
| ParallelDateTimeTupleEquality | Equality Type, Parallel DateTimeTuple | 991.25 ms | 2,371.67 ms | 129.999 ms | 6000.0000 | 26.7 MB |
| Method | Categories | Mean | Error | StdDev | Gen0 | Allocated |
|---|---|---|---|---|---|---|
| XS_SpaceTuple | Equality,XS | 92.99 ms | 167.30 ms | 9.170 ms | 3000.0000 | 12.21 MB |
| XS_DateTimeTuple | Equality,XS | 106.66 ms | 296.11 ms | 16.231 ms | 800.0000 | 3.81 MB |
| S_SpaceTuple | Equality,S | 232.32 ms | 366.75 ms | 20.103 ms | 4666.6667 | 19.84 MB |
| S_DateTimeTuple | Equality,S | 202.69 ms | 113.88 ms | 6.242 ms | 1250.0000 | 5.34 MB |
| M_SpaceTuple | Equality,M | 337.80 ms | 653.32 ms | 35.811 ms | 8666.6667 | 35.1 MB |
| M_DateTimeTuple | Equality,M | 243.01 ms | 62.83 ms | 3.444 ms | 2000.0000 | 8.39 MB |
| L_SpaceTuple | Equality,L | 475.74 ms | 164.05 ms | 8.992 ms | 16000.0000 | 65.61 MB |
| L_DateTimeTuple | Equality,L | 424.71 ms | 242.32 ms | 13.282 ms | 3000.0000 | 14.5 MB |
| XL_SpaceTuple | Equality,XL | 1,673.32 ms | 3,079.53 ms | 168.799 ms | 31000.0000 | 126.65 MB |
| XL_DateTimeTuple | Equality,XL | 1,080.35 ms | 2,256.74 ms | 123.700 ms | 6000.0000 | 26.7 MB |
| XXL_SpaceTuple | Equality,XXL | 2,392.21 ms | 4,022.31 ms | 220.476 ms | 62000.0000 | 248.72 MB |
| XXL_DateTimeTuple | Equality,XXL | 1,452.56 ms | 361.30 ms | 19.804 ms | 12000.0000 | 51.12 MB |
Some tuples require special treatment to make this process work. For example the DecimalTuple follows a slighly different flow! This is needed as there are no valid down casting of a decimal (at least not one that doesn't result in data loss). Looking at the implementation of the Equals method for DecimalTuple, we see:
- If the
Length(s) are different we returnfalseimmediatly. - If
Lengthis equal to 1, we avoid the vectorized equality check, and do a direct index search and equality as its a single operation eitherway. - We check if 256-bit vector operations are subject to hardware acceleration because a decimal is converted to its equivalent binary representation via 4
int(s). If the hardware supported only 128-bit vector operations it would result inVector<int>.Count = 4, which means 4intcomparission in parallel. While true that it would be a single processor instruction, so is the direct comparission between 2decimal(s), thereby we go this route only if there is 256-bit vector support as this allows equality checking between 4decimal(s) (2 fromthisand 2 fromother, as opposed to 1 fromthisand 1 fromother).
public bool Equals(DecimalTuple other)
{
if (Length != other.Length)
{
return false;
}
if (Length == 1)
{
return this[0] == other[0];
}
if (!Vector256.IsHardwareAccelerated)
{
return this.SequentialEquals<decimal, DecimalTuple>(other);
}
return new Comparer(this, other)
.AllocateAndExecute<int, Comparer>(8 * Length);
}We can note at the very end of this method that we create an instace of a Comparer and calling an extension method on it called AllocateAndExecute, and we provide a capacity of 8 * Length, this is because each decimal will be decomposed into 4 int(s), and we have 2 tuples to compare, so in total a capacity of 8 times the length of the tuple.
Looking closer at it, we see that it is a struct which implements the IBufferConsumer<T> interface. The comparer accepts 2 DecimalTuple(s) in the constructor (as it is special for the DecimalTuple) and implements the IBufferConsumer<T>. The Consume method accepts a buffer in the form of reference to a Span<int> (int because a decimal is converted to its equivalent binary representation via 4 int(s)). We split the buffer into 2 halfs, and loop through the tuple length (remember by this point we are ensured that the tuples have same number of fields) and decompose both decimal(s) of left & right which are the 2 DecimalTuple(s). The 4 int(s) of each decimal field are inserted into the respective half of the buffer that is given to us (magically, for now!). At the end we simply call ParallelEquals on the spans (the same method that was used for numeric and non-numeric tuples).
readonly struct Comparer : IBufferConsumer<int>
{
private readonly DecimalTuple left;
private readonly DecimalTuple right;
public Comparer(DecimalTuple left, DecimalTuple right)
{
this.left = left;
this.right = right;
}
public bool Consume(ref Span<int> buffer)
{
int tupleLength = left.Length;
int bufferHalfLength = buffer.Length / 2;
Span<int> leftSpan = buffer[..bufferHalfLength];
Span<int> rightSpan = buffer[bufferHalfLength..];
for (int i = 0; i < tupleLength; i++)
{
decimal.GetBits(left[i], leftSpan.Slice(i * 4, 4));
decimal.GetBits(right[i], rightSpan.Slice(i * 4, 4));
}
return leftSpan.ParallelEquals(rightSpan);
}
}Below we show benchmarks of instantiation and equality between using a SpaceTuple with only decimal fields, and using the dedicated DecimalTuple struct for 100,000 iterations. The letters S, M, L, XL, XXL denote the size of the tuples. We see that as the number of fields increases, so does the gap of performance between the generic and specialized tuple.
Note that there is a slight penalty in speed for DecimalTuple over a sequential version of DecimalTuple in equality checking for very small number of fields, but this goes away with an increased number of fields, and the memory allocation is far lower with any number of fields.
| Method | Categories | Mean | Error | StdDev | Median | Gen0 | Allocated |
|---|---|---|---|---|---|---|---|
| InstantiateSpaceTuple | Instantiation | 88.677 ms | 216.065 ms | 11.8433 ms | 81.893 ms | 19428.5714 | 77.82 MB |
| InstantiateDecimalTuple | Instantiation | 6.052 ms | 3.333 ms | 0.1827 ms | 6.118 ms | 6687.5000 | 26.7 MB |
| Method | Categories | Mean | Error | StdDev | Median | Gen0 | Allocated |
|---|---|---|---|---|---|---|---|
| SpaceTupleEquality | Equality Type, SpaceTuple | 473.302 ms | 1,919.140 ms | 105.1945 ms | 413.747 ms | 37500.0000 | 151.06 MB |
| SequentialDecimalTupleEquality | Equality Type, Sequential DecimalTuple | 112.906 ms | 798.243 ms | 43.7544 ms | 89.111 ms | 38333.3333 | 153.35 MB |
| ParallelDecimalTupleEquality | Equality Type, Parallel DecimalTuple | 129.359 ms | 51.212 ms | 2.8071 ms | 128.750 ms | 13500.0000 | 54.17 MB |
| Method | Categories | Mean | Error | StdDev | Median | Gen0 | Allocated |
|---|---|---|---|---|---|---|---|
| XS_SpaceTuple | Equality,XS | 16.370 ms | 16.909 ms | 0.9268 ms | 16.492 ms | 3437.5000 | 13.73 MB |
| XS_DecimalTuple | Equality,XS | 10.520 ms | 1.452 ms | 0.0796 ms | 10.479 ms | 2093.7500 | 8.39 MB |
| S_SpaceTuple | Equality,S | 32.501 ms | 63.880 ms | 3.5015 ms | 33.418 ms | 5718.7500 | 22.89 MB |
| S_DecimalTuple | Equality,S | 21.447 ms | 5.089 ms | 0.2789 ms | 21.384 ms | 2843.7500 | 11.44 MB |
| M_SpaceTuple | Equality,M | 59.794 ms | 101.439 ms | 5.5602 ms | 59.583 ms | 10200.0000 | 41.2 MB |
| M_DecimalTuple | Equality,M | 35.038 ms | 19.291 ms | 1.0574 ms | 35.190 ms | 4333.3333 | 17.55 MB |
| L_SpaceTuple | Equality,L | 113.140 ms | 5.227 ms | 0.2865 ms | 113.026 ms | 19500.0000 | 77.82 MB |
| L_DecimalTuple | Equality,L | 126.426 ms | 172.167 ms | 9.4371 ms | 126.493 ms | 7375.0000 | 29.75 MB |
| XL_SpaceTuple | Equality,XL | 303.626 ms | 929.585 ms | 50.9537 ms | 299.654 ms | 37666.6667 | 151.06 MB |
| XL_DecimalTuple | Equality,XL | 197.329 ms | 547.345 ms | 30.0018 ms | 184.540 ms | 13333.3333 | 54.17 MB |
| XXL_SpaceTuple | Equality,XXL | 554.220 ms | 455.510 ms | 24.9681 ms | 565.233 ms | 74000.0000 | 297.55 MB |
| XXL_DecimalTuple | Equality,XXL | 302.336 ms | 410.737 ms | 22.5139 ms | 315.260 ms | 25500.0000 | 103 MB |
We can clearly see the benefits of the parallelized approach, but one question remains.
Where does the buffer come from?
We previously mentioned an extension method called AllocateAndExecute. Let's examine it!
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static bool AllocateAndExecute<T, TConsumer>
(this TConsumer consumer, int capacity)
where T : unmanaged
where TConsumer : IBufferConsumer<T>
{
if (capacity * Unsafe.SizeOf<T>() <= 1024)
{
Span<T> buffer = stackalloc T[capacity];
return consumer.Consume(ref buffer);
}
else
{
T[] array = ArrayPool<T>.Shared.Rent(capacity);
Span<T> buffer = array.AsSpan();
bool result = consumer.Consume(ref buffer);
ArrayPool<T>.Shared.Return(array);
return result;
}
}We can see that it accepts an IBufferConsumer<T> where T is constraint to be an unmanaged type, it also accepts and int called capacity. The capacity is the total number of elements (matching the T generic parameter) you want to allocate. The method allocates the requested capacity in an efficient manner.
- In case where the multiplication of the
capacityand the size ofTis less or equal to 1024, it does so by means of allocating an array of such capacity on the stack. The bound to 1024 bytes is done intentionally! It's tempting to allocate as much as nearly possible on the stack, but different operating systems, architectures, and environments, have different stack limits. Therefor we play it safe and don't exceed the suggested 1 Kb limit. - If the limit is exceeded, than we resort to the ArrayPool, and rent such an array.
In either case we send a reference to the span of such allocated array to the consumer. If the array was rented from the pool, then once the Consume method returns we immediatly return the array to the pool. If the array was not rented but stack-allocated, than once the whole method returns (including the scope of the extension method) the stack will be emptied and the resource are returned to the operating system.
This is how the buffer came to be!
Overall this process significantly increase the performance of tuple equality, and while being useful for clients of this library for direct tuple equality, it also servers the library internally especially in the process of template matching which we will elaborate on.
Enumeration
Each tuple is enumerable, while true that there exist an indexer on the tuple which the user can use to enumerate the containing fields of the tuple via a for loop, like shown here:
SpaceTuple tuple = new(1, "linda", 1.5f);
for (int i = 0; i < tuple.Length; i++)
{
Console.WriteLine(tuple[i]);
}It is also possible to use a foreach loop to do the enumeration (the enumerator returned is a ReadOnlySpan<object>.Enumerator):
SpaceTuple tuple = new(1, "linda", 1.5f);
foreach (object field in tuple)
{
Console.WriteLine(field);
}Because all fields within a SpaceTuple are of type System.Object, the enumerator returns reference(s) to the field objects. In the case of specialized tuples, there are two ways how you can enumerate over the fields.
The 1st way is to declare the field as a value type, which will give you a copy of the original value:
IntTuple tuple = new(1, 2, 3);
foreach (int field in tuple)
{
Console.WriteLine(field); // field is a new 'int'
}The 2nd way is to declare the field as a reference type via ref readonly, which will give you a read-only reference to the value type:
IntTuple tuple = new(1, 2, 3);
foreach (ref readonly int field in tuple)
{
Console.WriteLine(field); // field is the original 'int'
}How you decide to enumerate specialized tuples dependes on the size of the underlying field type. Remember that references are IntPtr(s), so if the size of the field type is greater than the size of a reference, it makes sense to use a reference of the value type, to avoid copying the value.
The reason why the enumerator returns a "ref readonly" and not a "ref" is because the tuples are all immutable, therefor changing the fields after creation is not allowed.
String Representation
All tuples override ToString() and the result is all fields sepparated via ", " and enclosed in "()", for example:
SpaceTuple tuple1 = new(); // or 'default'
Console.WriteLine(tuple2.ToString()); // Outputs: ();
SpaceTuple tuple2 = new(1, "linda", 'a', 1.5f);
Console.WriteLine(tuple2.ToString()); // Outputs: (1, linda, a, 1.5);Specialized tuples have an extra method called AsSpan() which converts the contents of the tuple into a ReadOnlySpan<char>. You can use this method in cases where you want to manipulate the string representation, or want to send it to a different method but want to avoid a string allocation.
The generic SpaceTuple does not have the capability to be formatted to a span, because object doesn't implement ISpanFormattble as its derived type can be anything.
IntTuple tuple = new(3, 2, 1);
ReadOnlySpan<char> span = tuple.AsSpan();
DoSomethingWithSpan(span);
Console.WriteLine(span.ToString()); // Outputs: (3, 2, 1);
void DoSomethingWithSpan(ReadOnlySpan<char> span)
{
Console.WriteLine(span[0]); // Outputs: 3
Console.WriteLine(span[1]); // Outputs: 2
Console.WriteLine(span[2]); // Outputs: 1
}All of the specialized tuple's underlying type's (the .NET types that they can hold) currently implement ISpanFormattble, with the exception of bool. It is weird because System.Boolean does contain the TryFormat method of ISpanFormattble, but it doesn't implement the interface itself. There even exists an open (at the time of writting this article) issue related to this.
For bool we have employed a trick to get around this limitation. We use a custom wrapper struct SFBool around the bool which does implement ISpanFormattable.
readonly record struct SFBool(bool Value) : ISpanFormattable
{
public string ToString(string? format, IFormatProvider? formatProvider)
=> Value.ToString();
public bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider)
=> Value.TryFormat(destination, out charsWritten);
}And since the AsSpan<T, TTuple> extension method excepts only T(s) that are constraint to unmanaged and ISpanFormattable, and TTuple must be an ISpaceTuple<T>, we need to define a new struct that wraps around the individual SFBool(s), which is called creatively SFBoolTuple. Instead of passing the BoolTuple to the extension method, we pass a new SFBoolTuple to it and the formatting process works correctly even for boolean type tuples.
readonly record struct SFBoolTuple(params SFBool[] Fields)
: ISpaceTuple<SFBool>
{
public ref readonly SFBool this[int index] => ref Fields[index];
public int Length => Fields.Length;
public bool IsEmpty => Length == 0;
public ReadOnlySpan<char> AsSpan()
=> ReadOnlySpan<char>.Empty;
public ReadOnlySpan<SFBool>.Enumerator GetEnumerator() =>
new ReadOnlySpan<SFBool>(Fields).GetEnumerator();
}Templates
Templates are used for retrieval of tuples from the tuple space. The format of a template is (value1type1, value2type2, value3type3, ...). NULL values ARE allowed in a template.
Examples of templates are:
• temp1 (10int, NULL)
• temp2 (bookstring, NULL, NULL)
• temp3 (NULL, 25int, 30int, 300int, NULL)
The templates can have actual and formal values. Formal values are those which will be replaced during matching process. Actual values are those which will be compared during matching process. Hence the placeholder NULL is unique to templates as this would be replaced by that actual value when the template is matched against the tuple. For instance, if we want to retrieve the tuple "t1", we should give the template as tempA (4int, NULL, 10.65float). This will match the tuple "t1" and would retrieve the tuple and instead of the NULL placeholder it will have the value: lindastring.
Likewise the templates for the other tuples would be:
• t2 (parallelstring, cloudstring) —> tempB (NULL, NULL)
• t3 (25int, 100int, 99int) —> tempC (25int, NULL, NULL)
To match the tuple we should have the exact pattern and the exact number of fields:
• t3 (25int, 100int, 99int) —> temp (25int, NULL, NULL) [Correctly Matched]
• t3 (25int, 100int, 99int) —> temp (25int, NULL) [Incorrect number of fields]
• t2 (parallelstring, cloudstring) —> temp (lanstring, NULL) [Incorrect pattern]
Below we depict the same exaples written using the SpaceTemplate construct in OrleanSpaces.
SpaceTemplate temp1 = new(10, null);
SpaceTemplate temp2 = new("book", null, null);
SpaceTemplate temp3 = new(null, 25, 30, 300, null);Construction of a template via the default constructor results in a template with a single field, which is set to NULL, as a template without any fields would never be able to match anything in the tuple space.
Specialized Templates
For the same reasons why SpaceTuple kept all the fields stored in an array of object(s), so does SpaceTemplate (the generic version of a template). Templates are symmetrical to tuples, therefor for each specialized tuple, there exists a specialized template.
Specialized templates group all fields that belong to the same type. Below you can see instantiation of an IntTemplate and a compiler error in case mixed argument types are provided.
IntTemplate temp1 = new(1, 2, 3, null);
IntTemplate temp2 = new(1, 2, "linda", null); // CS1503: can not convert from "string" to "int"Equality
All templates implement the IEquatable<T> interface, where T is the template struct itself, therefor templates are equatable. Different from tuple equality, template equality can NOT be parallelized in the case of specialized templates! This limitation comes from the fact that templates (generic or specialized) must account for NULL fields at any index. This in-turn means that we can't use vectorized equality because NULL as a value makes no sense. Furthermore, switching to the default of the type in question, would yield to ambiguities (example: default(int) = 0 != null).
While this limitation may look problematic, its actually not! Because there aren't use-cases where template equality is performed within the library, and while true that users of the library may find such use-case useful for their application(s), the author doesn't see it being as common as tuple equality is.
With this fact in mind, we can lay down the rules which apply for two generic templates to be considered equal:
- The number of fields, must be the same.
- The types of fields on each index, must be the same.
- The values of fields on each index, must be the same (even for NULL's).
In the case of specialized templates, the check for the type on the field is not neccessary, as all fields are guaranteed to be of the same type. This in turn results in faster equality checks.
public bool Equals(SpaceTemplate other)
{
if (Length != other.Length)
{
return false;
}
for (int i = 0; i < Length; i++)
{
object? iLeft = this[i];
object? iRight = other[i];
if ((iLeft is null && iRight is not null) ||
(iLeft is not null && iRight is null) ||
(iLeft is { } l && !l.Equals(iRight)))
{
return false;
}
}
return true;
}Matching
The reading APIs provided by the agents accept templates to look for matching tuples in the tuple space. In the generic case of SpaceTuple-SpaceTemplate matching, the rules that apply can be summarized in the following way:
- The number of fields, must be the same.
- The types of fields on each index, must be the same.
- The values of fields on each index, must be the same, except when the respective field of the template is NULL, regardless of the type and/or value of the field (at the same index) in the tuple.
public bool Matches(SpaceTuple tuple)
{
if (tuple.Length != Length)
{
return false;
}
for (int i = 0; i < tuple.Length; i++)
{
if (this[i] is { } field)
{
if (field is Type templateType)
{
if (!templateType.Equals(tuple[i].GetType()))
{
return false;
}
}
else
{
if (!field.Equals(tuple[i]))
{
return false;
}
}
}
}
return true;
}In the case of specialized templates, this process can (and is) optimized to leverage the vectorized equality between 2 tuples. This is possible because any tuple can be converted to a template (the other way is not possible). This turned out to be so useful that an API (called ToTemplate) is exposed on each tuple to be converted into a respective template. Let's see how this process goes for one of the specialized templates (the process is the same for all types).
Looking into the IntTemplate, specifically the Matches method we see that in defers to an extension method call the same way.
public readonly record struct IntTemplate :
IEquatable<IntTemplate>,
ISpaceTemplate<int>,
ISpaceMatchable<int, IntTuple>
{
...
public bool Matches(IntTuple tuple)
=> this.Matches<int, IntTuple, IntTemplate>(tuple);
...
}Looking at the extension method Matches we can see that it accepts 3 generic type parameters T, TTuple, and TTemplate. This is done because accepting the interfaces ISpaceTuple<T> and ISpaceTemplate<T> as arguments would result in boxing of the structs, as interfaces are reference types. The constraints on T and TTemplate are self explanatory, but TTuple in addition to the ISpaceTuple<T> constraint, restricts usages to tuple structures which implement:
IEquatable<TTuple>- because we want to avoid a virtualized call toSystem.Object.Equals(object other)method, and instead call theIEquatable<TTuple>.Equals(TTuple other).ISpaceFactory<T, TTuple>- an interfaces which contains a static abstract member which composes aTTuplefrom an array ofTfields. It can be accessed off of the type parameterTTuplethat is constrained by the interface itself.
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static bool Matches<T, TTuple, TTemplate>(
this TTemplate template, TTuple tuple)
where T : unmanaged
where TTemplate : ISpaceTemplate<T>
where TTuple : ISpaceTuple<T>,
IEquatable<TTuple>, ISpaceFactory<T, TTuple>
{
...
}As depicted in the rules section, if the Length(s) of the tuple and template are different, we immediatly return false.
int length = template.Length;
if (length != tuple.Length)
{
return false;
}The interesting part comes now! Instead of looping through the length and checking each field of the template with that of the tuple (as we did in the generic case), we instead create a new tuple that has all fields of the template where the template contains values, and takes the field of the tuple (to be matched against the template) in cases where the field of the template at that index has a NULL value. This is valid because once we do vectorized equality check on the (now) 2 tuples, the fields of the template which are NULL will be replaced with the fields of the comparing tuple (which will result in equal fields, thereby equality on the field level is preserved).
Note the use of the static interface member TTuple.Create(fields) available from the ISpaceFactory<T, TTuple> constraint we declared above.
T[] fields = new T[length];
for (int i = 0; i < length; i++)
{
fields[i] = template[i] is { } value ? value : tuple[i];
}
TTuple templateTuple = TTuple.Create(fields);
bool result = templateTuple.Equals(tuple);
return result;At the end we just return the result of the equality comparission between tuple and templateTuple (the tuple created from the template). The process of equality is the same as we elaborated on the tuple equality section.
Enumeration
The enumeration works exactly the same way as we depicted in the enumeration section for the tuples, the only difference is that the enumerator contains nullable types. For example if the enumerator for IntTuple is ReadOnlySpan<int>.Enumerator, than the enumerator for IntTemplate is ReadOnlySpan<int?>.Enumerator.
Space
Consider having a blackboard, chalk, duster, some students, and a teacher. The teacher invites each of the students to go in front of the blackboard and contribute to solving a problem. Students go one-by-one and contribute a piece to the overall problem. Some students write using the chalk, some erase using the duster.
The blackboard is the same for all of them (a shared resource), and the teacher is the arbiter who controls that a single student (at a time) can write or erase from the blackboard.
Consider also that the students have their own pen and paper on which they can prototype their contribution to the overall problem beforehand. Some students who are interested on the overall progress on the problem sit and simply observer how the backboard content evolves over time.

The above mentioned scenario is very useful to describe the Tuple-Space Programming Model, as it align perfectly with the space concepts.
- The Chalk <=> The Tuple.
- The Duster <=> The Template.
- The Teacher <=> The Single-Threaded Model.
- The Blackboard <=> The Grain.
- The Student <=> The Agent.
We already described the chalk / tuple and the duster / template in the previous sections. Now we are going to focus on the other parts of the grand picture.
Single-Threaded Execution Model
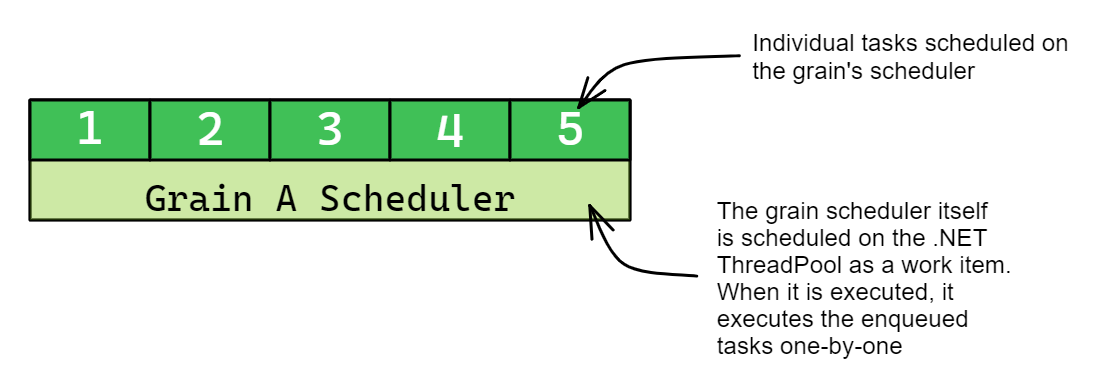
In order to achive this arbiter behaviour we make use of Orleans and its request scheduling
mechanism. The key to Orleans' simplicity and safety is the single-threaded execution model. Each grain is associated with a single thread on the host server. This means that all requests to a specific grain are processed one after the other on the same thread, ensuring that the grain's state is not accessed in parallel. Even if the request scheduling rules allow multiple requests to execute concurrently, they will not execute in parallel because the grain's task scheduler always executes tasks one-by-one.
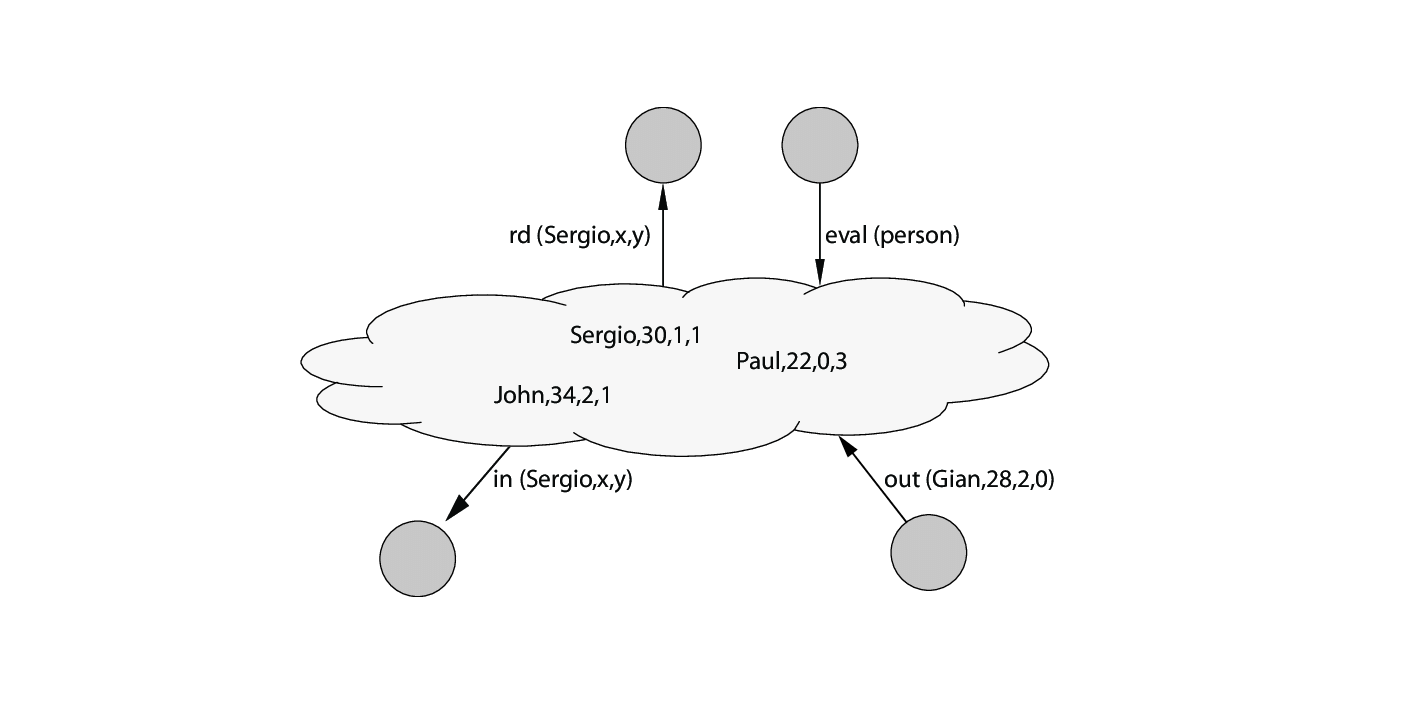
Space Grains
For each of the tuple-template pairs (generic and specialized), there exists a "blackboard". In OrleanSpaces these are implemented as grains. What kind of storage provider you want to use is totally irrelevant to the library (you may run everything in-memory, if you wish so), what is important is the single-threaded execution model that a grain has, that is the reason why grains has been chosen to be the bucket where tuples live.
All types of spaces have a dedicated grain, which simply extends a base class grain called creatively BaseGrain<T>, where T has constraints on being a struct type, must implement ISpaceTuple, and must implement IEquatable<T>. Note that all tuples implement IEquatable<T> where T is the type itself.
Much the same way as a grain is ever-existing (virtually), so does the tuple space. There is no need to ever create a space, because it always exists.
internal abstract class BaseGrain<T> : Grain
where T : struct, ISpaceTuple, IEquatable<T>
{
private readonly IPersistentState<List<T>> space;
private readonly StreamId streamId;
[AllowNull] private IAsyncStream<TupleAction<T>> stream;
public BaseGrain(string key, IPersistentState<List<T>> space)
{
streamId = StreamId.Create(Constants.StreamName, key ?? throw new ArgumentNullException(nameof(key)));
this.space = space ?? throw new ArgumentNullException(nameof(space));
}
public override Task OnActivateAsync(CancellationToken cancellationToken)
{
stream = this.GetStreamProvider(Constants.PubSubProvider).GetStream<TupleAction<T>>(streamId);
return Task.CompletedTask;
}
public ValueTask<ImmutableArray<T>> GetAll() => new(space.State.ToImmutableArray());
public async Task Insert(TupleAction<T> action)
{
space.State.Add(action.Tuple);
await space.WriteStateAsync();
await stream.OnNextAsync(action);
}
public async Task Remove(TupleAction<T> action)
{
var storedTuple = space.State.FirstOrDefault(x => x.Equals(action.Tuple));
if (!storedTuple.IsEmpty)
{
space.State.Remove(storedTuple);
await space.WriteStateAsync();
await stream.OnNextAsync(action);
}
}
public async Task RemoveAll(Guid agentId)
{
space.State.Clear();
await space.WriteStateAsync();
await stream.OnNextAsync(new(agentId, new(), TupleActionType.Clear));
}
}There isn't much interesting going on here. Some methods that insert, remove, and retrieve tuples from the state. The Insert and Remove methods accept a TupleAction<T> struct which is simply a wrapper struct with some metadata (which we'll revisit when we talk about the agents). One may also notice an IAsyncStream<TupleAction<T>> which signals changes made to the state of the grain. Note that due to the single-threaded execution model, it is safe to use a List<T> to group all tuples, as no two threads can modify it at the same time.
Space Agents
We are at the "meat and potatoes", namely the agent(s). For each of the tuple-template pairs (generic and specialized), there exists a dedicated agent that provides an interface to interact with the respective space. In our blackboard metaphor, it is the students who perform the actual work on the board, so do the agents in OrleanSpaces.
Here are some facts about the agents:
- All agent types provide the same set of functionalities.
- There exists only a single instance of each agent type (per process).
- The agent is thread-safe, therefor can be used in multi-threaded environments.
- The agent has a copy of the tuple space in-memory, therefor no network call is needed when searching for tuples.
- The tuple space content (i.e. the tuples) are continuously being replicated to the agent (on each process).
- The agent is transparently available all-the-time, and is available to the clients & servers.
- The agent supports the following communication models:
- Synchronous Request-Reply.
- Asynchronous Request-Reply.
- Publish-Subscribe.
- Streaming.
Generic Agent
In order to interact with the generic space, you need to use the ISpaceAgent interface which is available through dependency injection.
public interface ISpaceAgent
{
Guid Subscribe(ISpaceObserver<SpaceTuple> observer);
void Unsubscribe(Guid observerId);
Task WriteAsync(SpaceTuple tuple);
ValueTask EvaluateAsync(Func<Task<SpaceTuple>> evaluation);
ValueTask<SpaceTuple> PeekAsync(SpaceTemplate template);
ValueTask PeekAsync(SpaceTemplate template, Func<SpaceTuple, Task> callback);
IAsyncEnumerable<SpaceTuple> PeekAsync();
ValueTask<SpaceTuple> PopAsync(SpaceTemplate template);
ValueTask PopAsync(SpaceTemplate template, Func<SpaceTuple, Task> callback);
ValueTask<IEnumerable<SpaceTuple>> ScanAsync(SpaceTemplate template);
ValueTask<int> CountAsync();
Task ClearAsync();
}Below is a detailed overview of what each method does.
Subscribe- Registeres anything that implementsISpaceObserver<SpaceTuple>to the list of observers and notifies it on space events (which we'll discuss later). The method is idempotent, so multiple invocations of it, will result in a single registration of the observer.Unsubscribe- Enables observers to unsubscribe from space events, by providing theGuidthat was returned on the original subscription.WriteAsync- Directly writes the tuple to the space. The providedtuplemust be of non-zero length otherwise an exception is thrown.EvaluateAsync- Indirectly writes the tuple to the space. First it executes theevaluationfunction (which returns aSpaceTuple), and then proceeds to write it in the space.PeekAsync(template)- Reads aSpaceTuplethat is potentially matched by the giventemplate. If one such tuple exists, than a copy is returned thereby keeping the original in the space, otherwise a defaultSpaceTuplewith zero length is returned to indicate a "no-match" operation.PeekAsync(template, callback)- Reads aSpaceTuplethat is potentially matched by the giventemplate. If one such tuple exists, thecallbackis invoked immediately, otherwise the operation is remembered and thecallbackwill eventually be invoked as soon as a matchingSpaceTupleis written in the space.PeekAsync()- Reads a stream ofSpaceTupleas they are written in the tuple space. Wether multiple readers can or can't read from the same stream depends on the configuration set by the clients of the library via theSpaceOptions.AllowMultipleAgentStreamConsumers(multiple readers are set as default).PopAsync(template)- Reads aSpaceTuplethat is potentially matched by the giventemplate. If one such tuple exists, then the original is returned thereby removing it from the space, otherwise aSpaceTuplewith zero length is returned to indicate a "no-match" operation.PopAsync(template, callback)- Reads aSpaceTuplethat is potentially matched by the giventemplate. If one such tuple exists, thecallbackis invoked immediately, otherwise the operation is remembered and thecallbackwill eventually be invoked as soon as a matchingSpaceTupleis written in the space.ScanAsync- Reads multipleSpaceTuple(s) that are potentially matched by the giventemplate. Same as withPeekAsync(template), the original tuple(s) are kept in the space, only copies are returned.CountAsync- Returns the total number ofSpaceTuple(s) in the space.ClearAsync- Removes allSpaceTuple(s) from the space.
Below a table is given which categorize the agent methods based on communication model they employ.
| Method | Model |
|---|---|
| WriteAsync | Synchronous Request-Reply |
| PeekAsync(template) | Synchronous Request-Reply |
| PopAsync(template) | Synchronous Request-Reply |
| EvaluateAsync | Asynchronous Request-Reply |
| PeekAsync(template, callback) | Asynchronous Request-Reply |
| PopAsync(template, callback) | Asynchronous Request-Reply |
| PeekAsync() | Streaming |
| Subscribe | Publish-Subscribe |
| Unsubscribe | Publish-Subscribe |
Specialized Agents
As mentioned earlier, for each tuple-template pair there exists a respective agent that provides the same set of functionalities as the generic one, but tailored towards a single specialized pair. In order to interact with the specialized space(s), you need to use the ISpaceAgent<T, TTuple, TTemplate> interface which is available through dependency injection. When you inject the interface in the component, you specify which agent you want to use by means of setting the generic type arguments on the interface level.
For example, if you want to make use of the agent tailored towards the int space, you do it like this:
class MyClass
{
ISpaceAgent<int, IntTuple, IntTemplate> agent;
public MyClass(ISpaceAgent<int, IntTuple, IntTemplate> agent)
=> this.agent = agent;
public Task DoWrite()
=> agent.WriteAsync(new IntTuple(1, 2, 3));
}The ISpaceAgent<T, TTuple, TTemplate> interface is strongly-typed, therefor operations like the one below won't compile. This has been done intentionally in order to provide a type-safe environment for the clients, and mitigate potential writes/reads from/to the wrong space.
ISpaceAgent<int, IntTuple, IntTemplate> agent = ...
agent.WriteAsync(new BoolTuple(true, false)); // won't compile (CS1503)If you inject the specialized agent interface in a lot of places, and want to avoid typing ISpaceAgent<int, IntTuple, IntTemplate> everywhere, you can always use global using aliases.
global using IIntAgent = OrleanSpaces.ISpaceAgent<int,
OrleanSpaces.Tuples.Specialized.IntTuple,
OrleanSpaces.Tuples.Specialized.IntTemplate>;
namespace Namespace1
{
class Class1
{
public Class1(IIntAgent agent)
{
}
}
}
namespace Namespace2
{
class Class2
{
public Class2(IIntAgent agent)
{
}
}
}⚠️ All agents are isolated between each other, therefor the tuple spaces are also isolated. An action performed on say the int agent, has not effect whatsoever on say the bool agent, generic agent and so on.
We won't go into the details of what each method of this interface does because they are effectively the same as in the generic agent described above. One thing that is important to highlight is the fact that not all agent types are "active" via the default configuration of the SpaceOptions. Only the generic agent is set to run upon program startup. In order for the client to make use of the other agents, they need to explicitly "turn them on", via specifying the SpaceOptions.EnabledSpaces.
You can configure them via bitwise OR operation, like this:
AddOrleanSpaces(o => o.EnabledSpaces = SpaceKind.Generic | SpaceKind.Int);Or if you want to run all agents you can use the All enum value.
AddOrleanSpaces(o => o.EnabledSpaces = SpaceKind.All);Space Observers
In the generic agent section above we mentioned the different communication models, but also the Subscribe and Unsubscribe methods on the agent itself. As the names' imply, these methods are use to subscribe and unsubscribe, but what exactly is the thing that subscribes to space events?
Any component that implements the ISpaceObserver<T> interface is considered to be a space observer. Note that the constraint on T is any kind of tuple (expressed via the ISpaceTuple interface), which means that the same observer interface is used for both generic and specialized tuples (which makes things easier for the client).
public interface ISpaceObserver<T> where T : ISpaceTuple
{
Task OnExpansionAsync(T tuple, CancellationToken cancellationToken = default);
Task OnContractionAsync(T tuple, CancellationToken cancellationToken = default);
Task OnFlatteningAsync(CancellationToken cancellationToken = default);
}Below is a detailed overview of what each method does.
OnExpansionAsync- Occurs whenever a tuple is written in the space. TheTparameter is the tuple that got written.OnContractionAsync- Occurs whenever a tuple is removed from the space. TheTparameter is the tuple that got removed.OnFlatteningAsync- Occurs whenever the space gets emptied, which means it contains zero tuples.
In addition to the interface, there exists an abstract class called SpaceObserver<T> which implements ISpaceObserver<T>, and but it does not override the interfaces' methods (those are left to the client code). What this class offers is what I call dynamic observation capabilities. The observer component can specify on what kind of space events it wants to be notified. In addition, the selection of event types can be changed dynamically during runtime.
public class MyObserver : SpaceObserver<SpaceTuple>
{
public MyObserver() => ListenTo(Expansions);
public override Task OnExpansionAsync(
SpaceTuple tuple, CancellationToken cancellationToken)
{
ListenTo(Contractions);
return Task.CompletedTask;
}
public override Task OnContractionAsync(
SpaceTuple tuple, CancellationToken cancellationToken)
{
ListenTo(Flattenings);
return Task.CompletedTask;
}
public override Task OnFlatteningAsync(
CancellationToken cancellationToken)
{
ListenTo(Nothing);
return Task.CompletedTask;
}
}The MyObserver specifies in the contructor that it wants to listen to Expansion events via the ListenTo method. This means that this observers' only method that will be invoked will be the OnExpansionAsync. But notice also that within this method, we invoke again the ListenTo method, but specify that now this observer wants to listen to Contraction events only. Notice again that now within this method we invoke the ListenTo method, but specify that now this observer wants to listen to Flattening events only. Notice again that within the OnFlatteningAsync we specify that now we don't want to listen to any kind of events.
That's why it is called dynamic! These Expansions, Contractions, Flattenings, Nothing are static fields within the SpaceObserver<T> class, and are available only to derived types. There are a total of 5 event types, given via the EventType enum, that is also available only to the derived types. There is also the Everything event type that we didn't use in the above observer example, which specifies that the observer is interested in all 3 event types.
⚠️ By default, derived types of
SpaceObserver<T>are configured to listen to all types of events.
[Flags]
protected enum EventType
{
Nothing = 0,
Expansions = 1,
Contractions = 2,
Flattenings = 4,
Everything = Expansions | Contractions | Flattenings
}Architecture
The "space" is not a particular component, it is the interaction of multiple components. It is not a single place, it is a distributed space. In order to have a clear picture of what goes under the hood, we can refer to the simplified architecture diagram below.
From the diagram we can see these core components:
- Agent
- Grain
- Router
- Channels
- Registries
- Processors
We already elaborated in detail the agent and the grain, so now we are going to look into the other components.
Router
Looking at the diagram we can see that the router is called from the Continuation and Space processors. The continuation processor sends tuples and/or templates to the router, which in turn routes the data structure to the appropriate method within the agent. The space processor also calls the router in order to inject the store (which is going to be the grain), and to route TupleAction(s) (which we mentioned on the space grains section).
internal interface ISpaceRouter<TTuple, TTemplate>
where TTuple : ISpaceTuple
where TTemplate : ISpaceTemplate
{
void RouteStore(ITupleStore<TTuple> store);
Task RouteTuple(TTuple tuple);
ValueTask RouteTemplate(TTemplate template);
ValueTask RouteAction(TupleAction<TTuple> action);
}While the router is an interface, the actual implementation of it IS the agent. The reason for not having these methods within the ISpaceAgent interface is due to the interface being public and the implementation being internal. It also shows the Interface Segregation Principle in play.
Channels
Continuing the journey on the internals, from the diagram we can see the use of 4 channels. These channels are derived types of System.Threading.Channels.Channel<T>. These are synchronization data structures for passing data between producers and consumers asynchronously. Below is a detailed overview of what each channel does.
Do not confuse async/await with these flows! These are truly asynchronous, that is the invoking method of the calling code can actually return without the flow finishing.
EvaluationChannel - In this channel we can write & read only
ISpaceTuple(s). The agent writes to the channel upon invocations of itsEvaluateAsyncmethod. The EvaluationProcessor is the one that reads the written tuples from the agent, and pushes them to the ContinuationChannel.CallbackChannel - In this channel we can write & read only
ISpaceTuple(s). The agent writes to the CallbackRegistry upon invocations of its methods that accept aFunc<SpaceTuple, Task>callback. The SpaceProcessor is the one that writes tuples to the channel as they come in. The CallbackProcessor is the one that reads tuples from the channel, and depending wether callbacks which are present in the registry match the read tuple(s), it proceeds to invoke the callback that matched it in the first place. The callback is then removed from the registry as it has been completed.ObserverChannel - In this channel we can write & read only
TupleAction<T>(s) whereTis anISpaceTuple. The agent writes to the ObserverRegistry upon invocations of itsSubscribemethod. Before entering the reference of the observer in the registry, there is an intermediate step that is performed (which we'll elaborate in the registries section). The SpaceProcessor is the one that writes actions to the channel as they come in. The ObserverProcessor is the one that reads actions from the channel, and pushes to the observers' internalNotifyAsyncmethod, which depending on the actions'TupleActionTypeproperty, knows which of the observers' method to invoke (or ignore).ContinuationChannel - This is the only channel that we can write & read
ISpaceTuple(s) andISpaceTemplate(s). It is both, the EvaluationProcessor and CallbackProcessor that write to the channel. The EvaluationProcessor writes tuples, while the CallbackProcessor writes templates. Note that the CallbackProcessor writes templates ONLY if the callback has a continuation (these are callbacks that have a continuation job to perform AFTER the callback has been executed). The ContinuationProcessor is the one that reads both the tuples and templates from the channel. It proceeds to push them to the router (which we covered above).
Registries
From the diagram we can see the use of 2 registries. These are buckets that store references to callbacks and observers.
Observer Registry
Looking into the ObserverRegistry<T> we can see that it adds and removes references to ISpaceObservers<T> where T is an ISpaceTuple. The observer references are stored in a ConcurrentDictionary since this is called from the agent and multiple threads can access the same agent instance (eventhough its a singleton). Note that the reference to the observer is the key of the dictionary, this allows unique references to be stored therefor making the observer subscription process idempotant.
As mentioned in the channels section above, there is an intermediate step that happens before entering the reference of the observer in the registry. Inside the Add method we can see that it is first determined wether the reference is a type which derives from SpaceObserver<T> or if its an implementation of the ISpaceObserver<T>. In the later case, the direct implementation of the interface is wrapped in a decorator which acts as an internal representation of a derived class of SpaceObserver<T> which has EventType.Everything turned on by default, this aligns with the logic of a component directly implementing the interface.
internal sealed class ObserverRegistry<T>
where T : ISpaceTuple
{
private readonly ConcurrentDictionary<SpaceObserver<T>, Guid> observers = new();
public IEnumerable<SpaceObserver<T>> Observers => observers.Keys;
public Guid Add(ISpaceObserver<T> observer)
{
if (observer == null)
{
throw new ArgumentNullException(nameof(observer));
}
SpaceObserver<T> _observer = observer is SpaceObserver<T> spaceObserver ?
spaceObserver : new ObserverDecorator<T>(observer);
if (!observers.TryGetValue(_observer, out _))
{
observers.TryAdd(_observer, Guid.NewGuid());
}
return observers[_observer];
}
public void Remove(Guid id)
{
SpaceObserver<T> key = observers.SingleOrDefault(x => x.Value == id).Key;
if (key != null)
{
observers.TryRemove(key, out _);
}
}
}Callback Registry
Looking into the CallbackRegistry<T, TTuple, TTemplate> we can see that it adds and removes CallbackEntry<T>(s), where T is an ISpaceTuple. The entry is simply a wrapper struct that contains the actual callback and a flag called HasContinuation which is an indicator to the ContinuationProcessor wether to perform a job after the execution of the callback or not.
internal readonly struct CallbackEntry<T>
where T : ISpaceTuple
{
public readonly Func<T, Task> Callback;
public readonly bool HasContinuation;
public CallbackEntry(Func<T, Task> callback, bool hasContinuation)
{
Callback = callback;
HasContinuation = hasContinuation;
}
}The actual registry contains 2 methods. Add, which accepts a template and a callback entry. The template is the key of the dictionary, since all the templates implement IEquatable<T>, where T is the type itself, we can be assured that no boxing occurs.
⚠️ By default the CLR provides the default implementations for Equals and GetHashCode that follows "value semantics", i.e. the two instances of a struct are equal when all the fields are equals. But unfortunately, the calling a default Equal or GetHashCode methods causes boxing allocation and may be implemented using reflection, which can be slow.
For a given tuple, Take; loops through the entries and yield returns all entries where the template on the key of the dictionary matches (the process elaborated in the template-matching section) the given tuple. The matching process can take place as the generic parameter TTemplate is constraint to not only ISpaceTemplate<T>, but also to ISpaceMatchable<T, TTuple> which declares this method. The entry is then removed from the dictionary.
internal sealed class CallbackRegistry<T, TTuple, TTemplate>
where T : unmanaged
where TTuple : ISpaceTuple<T>
where TTemplate : ISpaceTemplate<T>, ISpaceMatchable<T, TTuple>
{
private readonly ConcurrentDictionary<TTemplate, List<CallbackEntry<TTuple>>> entries = new();
public ReadOnlyDictionary<TTemplate, ReadOnlyCollection<CallbackEntry<TTuple>>> Entries =>
new(entries.ToDictionary(k => k.Key, v => v.Value.AsReadOnly()));
public void Add(TTemplate template, CallbackEntry<TTuple> entry)
{
if (!entries.ContainsKey(template))
{
entries.TryAdd(template, new());
}
entries[template].Add(entry);
}
public IEnumerable<CallbackEntry<TTuple>> Take(TTuple tuple)
{
foreach (var pair in entries)
{
if (pair.Key.Matches(tuple))
{
foreach (var entry in entries[pair.Key])
{
yield return entry;
}
entries.TryRemove(pair.Key, out _);
}
}
}
}Processors
From the diagram we can see the use of 5 processors. These are background service that are started when the host is started and together with the agent they continuously move elements such as: tuples, templates, actions, entries. While true that the elements move through channels, it is the processors that mostly initiate this movement. You can think of them as the battery in an electric circuit which induces a force field that propagates in the form of electric current, where elements of space are like the electrons in a circuit, and the channels are the circuits.
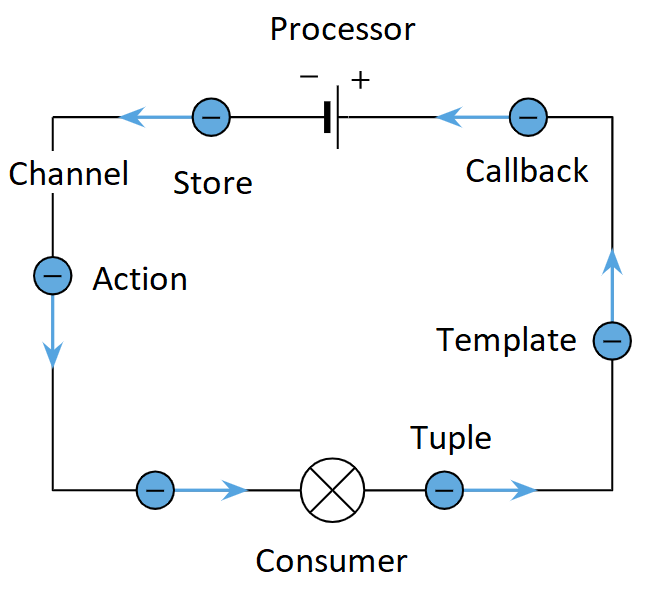
We mentioned the individual processors and their roles quite a bit the the channels section above. But it doesn't hurt to give a recap of their roles:
EvaluationProcessor - Its role is to read tuples from the EvaluationChannel and push them to the ContinuationChannel. Clients can specify wether or not the processor should handle exceptions that may arise in their code via the
SpaceOptions.HandleEvaluationExceptions(set totrueby default).CallbackProcessor - Its role is to read tuples from the CallbackChannel and execute those callbacks when a template from the CallbackRegistry matches the current tuple. Also if a callback has a continuation, the current tuple is converted to a template and pushed to the ContinuationChannel. Clients can specify wether or not the processor should handle exceptions that may arise in their callback code via the
SpaceOptions.HandleCallbackExceptions(set totrueby default).ObserverProcessor - Its role is to read actions from the ObserverChannel and push the action to the observers (they each determine wether to invoke the given methods or not).
ContinuationProcessor - Its role is to read tuples & templates from the ContinuationChannel and push them to the router.
SpaceProcessor - It can be sepparated into two phases:
- Pre-processing
- Upon startup it pushes the
ITupleStore<T>to the router. - Subscribes to an implicit stream of the SpaceGrain.
- Upon startup it pushes the
- Processing
- Pushes actions that arrive to the router.
- Pushes actions that arrive to the ObserverChannel, ONLY if
SpaceOptions.SubscribeToSelfGeneratedTuplesis set totrue(set totrueby default). - Pushes the tuples wrapped in the actions to CallbackChannel, ONLY if the
TupleActionTypeproperty of the action isTupleActionType.Insert.
- Pre-processing
Analyzers
In order to guide the consumers of this library, some best practice analyzers & fixers have been developed and are distributed as a sepparate NuGet package. The analyzers are prefixed with OSA, followed by the number.
OSA001
- Severity: Warning
- Category: Usage
- Code Fix: Not available
Interface is intended for internal use only.
The interfaces ISpaceTuple, ISpaceTemplate and the generic versions ISpaceTuple<T>, ISpaceTemplate<T> are used by the internals of the library. They are not intended to be used, cast to/from, and/or implemented by client code. Always use the concrete tuple/template types exposed by the library.
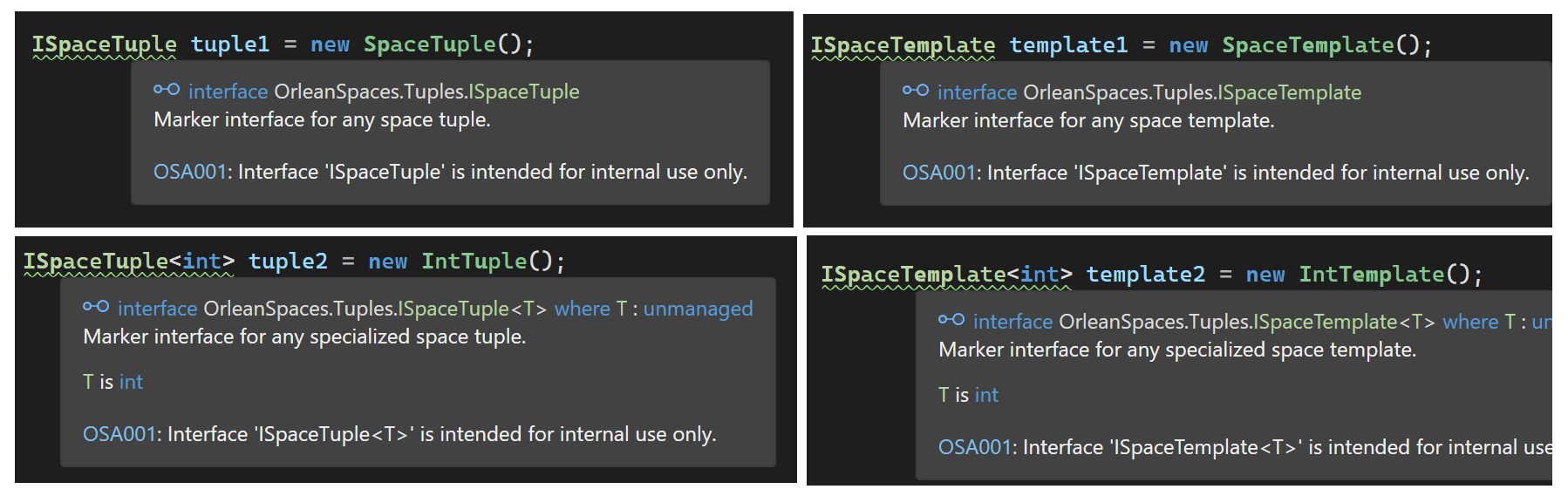
OSA002
- Severity: Info
- Category: Performance
- Code Fix: Available
Avoid constructor instantiation having only NULL type, or no arguments.
Instantiation of a SpaceTemplate having only null type arguments (or no arguments) means that you care about tuples having that many fields, but don't care for the types, values, or indices.
SpaceTemplate template = new SpaceTemplate(null, null, null);The above results in the creation of an array of objects with 3 items, all of which are of type null. This results in unnecessary memory allocations, not because of the SpaceTemplate (as its a struct) but the allocation of the internal array. Since an 'x-template' always has the same number of fields, one can (and should) reuse that via a read-only reference to an already initialized 'x-template', in order to avoid allocations. A code fixer is available to take care of this.

OSA003
- Severity: Error
- Category: Usage
- Code Fix: Available
The supplied argument type is not supported.
When arguments passed to a SpaceTuple or SpaceTemplate are not supported types, an ArgumentException is thrown during runtime. This analyzer detects such types and reports errors to the user. A code fixer is available to take care of this.
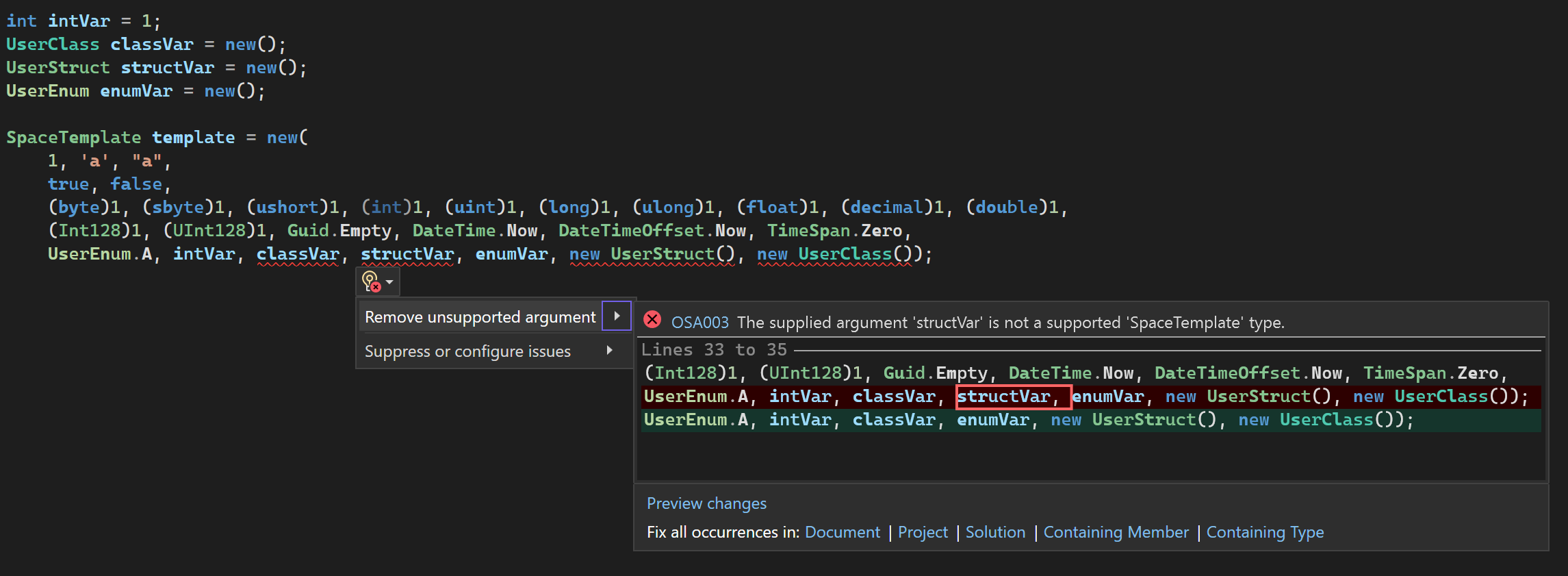
Case Studies
The Tuple-Space Programming Model (TSPM) is especially useful in "divide and conquer" problems. Below are some ways that tuple space can be relevant to.
- Task Distribution - In a divide and conquer algorithm, tasks are divided into smaller subtasks. TSPM can be used to distribute these subtasks across multiple processing units or nodes, enabling parallel processing of the subproblems.
- Result Aggregation - Once the subproblems are solved independently, their results need to be aggregated to obtain the final solution. TSPM can be used to collect and combine the results from different nodes in a decentralized and scalable manner.
- Load Balancing - Divide and conquer algorithms may have varying complexities for different subproblems. TSPM can help balance the load by distributing subproblems based on their complexity or availability of computational resources.
- Fault Tolerance - When using distributed computing for divide and conquer, failures of nodes or tasks may occur. TSPM can help in handling fault tolerance by ensuring that failed tasks are retried or reassigned to other available nodes.
- Recursive Subdivision - Some divide and conquer algorithms involve recursive subdivision of problems into smaller instances. TSPM can be employed to manage the organization of these recursive steps.
One important thing to keep in mind is that the case studies presented below, do not mean that they represent a "better" way to handle such problems. It can even be that they incur penalties. They are just to illustrate how TSPM could be used to solve them. As with every kind of parallelizable algorithm, typically you gain value when the number of degress of freedom increases.
Password Search
The aim of this application is to find a password using its hashed value in a predefined "database", distributed among processes. Such a database is a set of files containing pairs (password - hashed value). The application creates a master process and several worker processes. The master keeps asking the workers for passwords corresponding to a specific hashed values by issuing tuples of the form:
("hash", dd157c03313e452ae4a7a5b72407b3a9i)
Each worker first loads its portion of the distributed database and then obtains from the master a task to look for the password corresponding to a hash value. Once it has found the password, it sends the result back to the master, with a tuple of the form:
("password", dd157c03313e452ae4a7a5b72407b3a9, 7723567i)
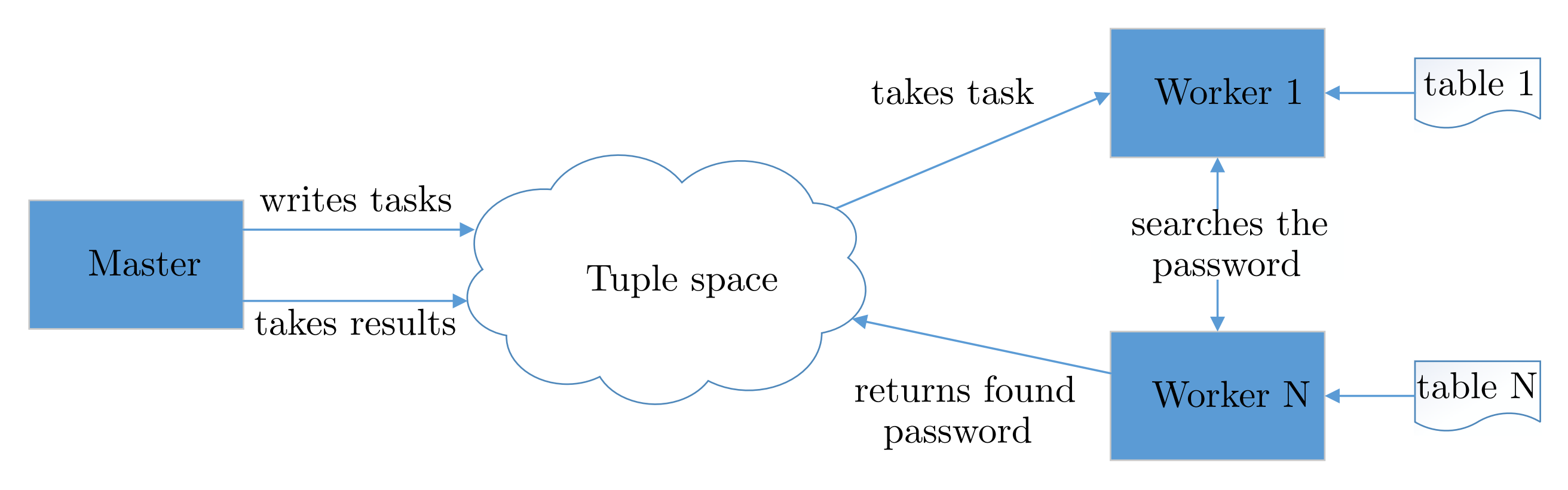
The example above would use the generic SpaceTuple, but since the password hash always returns the same number of characters, we can use the specialized CharTuple in the form:
('h', 'd', 'd', ..., '9', 'i')
Where the first field of the tuple, namely 'h' can encode "hash". Similarly for the workers:
('p', 'd', 'd', ..., '9', 'i', '7', '7', ..., '7', 'i')
Where the first field of the tuple, namely 'p' can encode "password". And since the the number of characters is always the same for the result of "hash+xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", master can take the rest of the characters and compose the solved password.
Array Sorting
The aim of this application is to sort an array of integers. The master is responsible for loading initial data and for collecting the final sorted data, while workers are directly responsible for the sorting. At the beginning, the master loads predefined initial data to be sorted and sends them to the tuple space. Afterward, the master waits for the sorted arrays from the workers: when any sub-array is sorted the master receives it and when all sub-arrays are collected, it builds the whole sorted sequence. The master can send IntTuple(s) of the form:
(0, 8, 3, 4, 2, 7, 2, 4, 1)(1, 9, 4, 5, 3, 8, 3, 5, 2)...(99, 5, 4, 5, 4, 8, 3, 5, 2)
Where the first number indicates which array it is and the rest are the individual elements of array itself.
The behavior of workers is different. When they are instantiated, each of them starts searching for the unsorted data in the tuple space. When a worker finds a tuple with unsorted data, it checks whether the size of such data is below the predetermined threshold and in such a case it computes and sends the result back to the tuple space (which the master picks up), then it continues by searching for other unsorted data. The workers can send back a.k.a "return" IntTuple(s) of the form:
(0, 3, 8)(0, 2, 4)(0, 2, 7)(0, 1, 4)...(99, 4, 5)(99, 4, 5)(99, 3, 8)(99, 2, 5)
Where the first number indicates which array it is and the other 2 numbers are the sorted integers of the subset picked up from a worker. In the end the master can assemble these 4 tuples into an array of sorted integers:
- 12234478
- 23345589
- 23445558
Matrix Multiplication
The aim of this application is to multiply two square matrices of the same order. The algorithm of multiplication operates with rows of two matrices A and B and put the result in matrix C. The latter is obtained via subtasks where each row is computed in parallel. At the ith step of a task, the element ai1 of A is multiplied by all the elements of the ith row of B; the obtained vector is added to the current ith row of C. The computation stops when all subtasks terminate. The figure below shows how the first row of C is computed if A and B are 2 × 2 matrices.
- In the first step, the element a11 is multiplied first by b11 then by b12, to obtain the first partial value of the first row of C.
- In the second step, the same operation is performed with a12, b21, b22 and the obtained value is added to the first row of C thus obtaining its final value.
Initially, the master writes the B matrix in the space, subsequently 2 workers read that value and keep it locally.
("B", b11, b12, b21, b22)
Next the master divides matrix A into vectors for each column of the matrix.
("A", a11, a21)("A", a12, a22)
Each worker reads one of the vectors and performs the calculations mentioned above. Each worker computes the ith row of matrix C, and send back their result to the space.
Worker 1: ("C", a11 * b11, a11 * b12, a21 * b11, a21 * b12) = ("C", c11, c12, c13, c14)
Worker 2: ("C", a12 * b21, a12 * b22, a22 * b21, a22 * b22) = ("C", c21, c22, c23, c24)
The master picks those vectors and simply adds them together, thereby obtaining the final result of the multiplication of A and B.
("C", c11 + c21, c12 + c22, c13 + c23, c14 + c24)
There are some things to note here:
While we used the strings A, B, C to identify the matrices, if the values a, b, c where say positive integers we could substitute those with some predetermined values like: -1, -2, -3 to encode those informations. This would allow us to use the specialized
IntTupleover the genericSpaceTuple.In the above example we have choosen to split the work into 2 workers. If the matrices were 3x3 it would be 3 workers, and so on. But we could have choosen to dedicate a worker-per-cell, where each worker would compute the neccessary intermediate multiplications of a single cell of matrix A with the rest of elements from matrix B, and at the end the master would aggregate those like: ("C", c11 + c21 + ... + cn1, c12 + c22 + ... + cn2, + ...)
The matrices are flattened into vectors since tuples are 1-dimensional constructs. The end result can easily be extrapolated from the end tuple via trivial application logic.
Summary
The Tuple-Space Programming Model (TSPM) is a powerful distributed computing paradigm that enables efficient communication and coordination between components in a decentralized environment. At its core, TSPM relies on the concept of a "tuple space," where data is stored in tuples and accessed through agents via templates. Tuples are immutable data structures, and agents act as interfaces to read and write tuples in the tuple space. The model supports both generic and specialized tuples, providing a type-safe environment for clients.
The architecture of TSPM comprises various components, including agents, grains, routers, channels, registries, and processors. The agents handle tuple interactions, grains represent individual tuple spaces, routers route tuples to the appropriate agent methods, and channels facilitate asynchronous data transfer between producers and consumers. Registries store references to callbacks and observers, while processors are background services that continuously move elements through the system.
Case studies demonstrate the versatility of TSPM, showcasing its application in diverse scenarios such as password search, array sorting, and matrix multiplication. TSPM excels in "divide and conquer" problems, enabling task distribution, result aggregation, load balancing, and fault tolerance.
The use of specialized tuples greatly improves performance, and careful consideration of parallelization helps optimize performance for large-scale problems. Overall, TSPM provides a robust and efficient approach to distributed computing, offering a reliable solution for a wide range of applications.
If you found this article helpful please give it a share in your favorite forums 😉.
The solution project is available on GitHub.